Signed-off-by: kjuulh <contact@kjuulh.io>
21 KiB
type, title, description, draft, date, updates, tags
| type | title | description | draft | date | updates | tags | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| blog-post | Projects of 2025 | false | 2026-01-20 |
|
|
We're now well into 2026, and it has been a while since I've written a blog post. So why not start off with a little retrospective? 2025 was a year of change for me, and initially I wasn't going to write this post, as I've been busy with life and work; started new job in a start-up, and moved into my first house (on the same day...) planning has never been my strong suit.
In this post I am going over a few projects I've written for myself, and work, often because I have difficulty separating the two. I simply like to produce stuff that is useful, and that can often be used at work as well.
As it has been a while since I've posted anything, and if you've read previous posts of mine, you might be surprised to know that I am now working in the data space, and that is where my focus has been since end 2024 until now.
Let's jump straight into the projects shall we.
I should mention that some of the tools were developed using Claude. But was mostly used for refactorings and writing up documentation etc. I don't actually like many of the parts that were developed using Claude, so I am planning on ripping them out, and only using Claude at the "edge" of the projects
Personal Productivity
This is a bunch of tools I've created to expand my workflow, I live on the terminal pretty much always, so these are convenience tools to help me have more fun, be more efficient etc.
GitNow
[▮▮▮▮▮▮▮▮▮▮] 7939 hx
[▮▮▮▮▮▮ ] 5046 cargo run
[▮▮▮▮▮ ] 4278 jj
[▮▮▮▮▮ ] 4202 gca
[▮▮▮▮ ] 3567 ,
[▮▮▮ ] 2834 ranger
[▮▮ ] 2321 gp
[▮▮ ] 2113 m
[▮▮ ] 1902 gs
[▮▮ ] 1888 rg
history of commands I've run in 2025 on my personal pc
I use git (jujutsu) a lot, and have a lot of projects I work on, both at work and personally. 105 personal project checked out, 244 for work. Zoxide is a great tool to use to move between them, but often I end up in this situation.
- Let me go to this project
- Dang I don't have it checked out
- Go to github or my own git.kjuulh.io gitea instance
- Search for project
- Click copy ssh
- cd into ~/git/git.kjuulh.io/kjuulh and run git clone
<repo> - cd
<repo>
Often you could just clone directly, but often when I don't have it checked out, I am not 100% sure about the name of the repo.
That is why I built GitNow. Seriously it is a small tool, but it brings me joy every time I use it, even if it is brief (as it should be)
GitNow allows me to quickly fuzzy search repos, move the current console to the placement, or clone the sucker. It brings at task down from 30 seconds down to 2 seconds, and it does double duty simply because it just allows me to move between repos if I've already got it down, replacing zoxide for me. It caches the responses from the forges you subscribe to, so it doesn't have to wait for any network calls, and quietly updates the cache in the background.
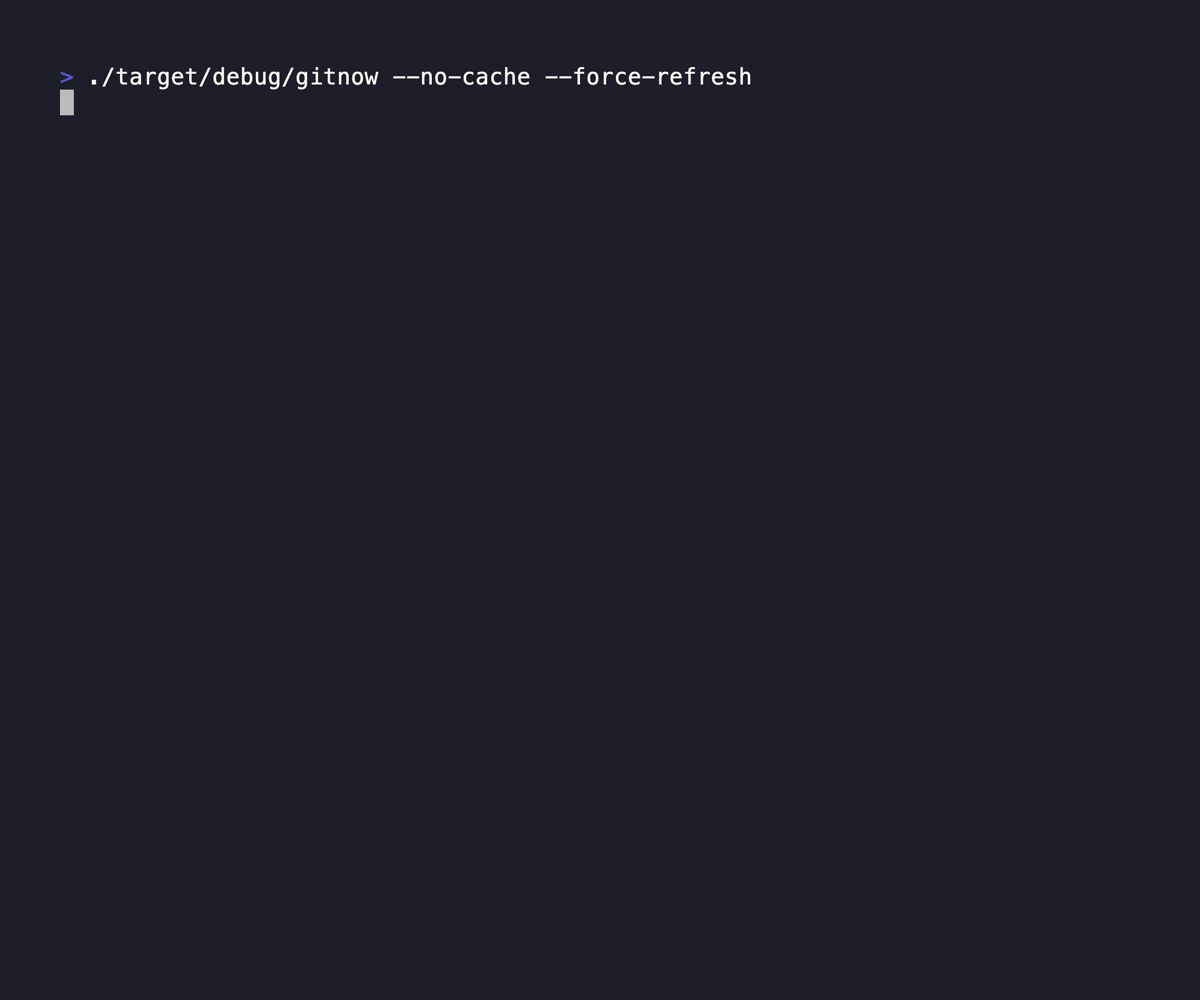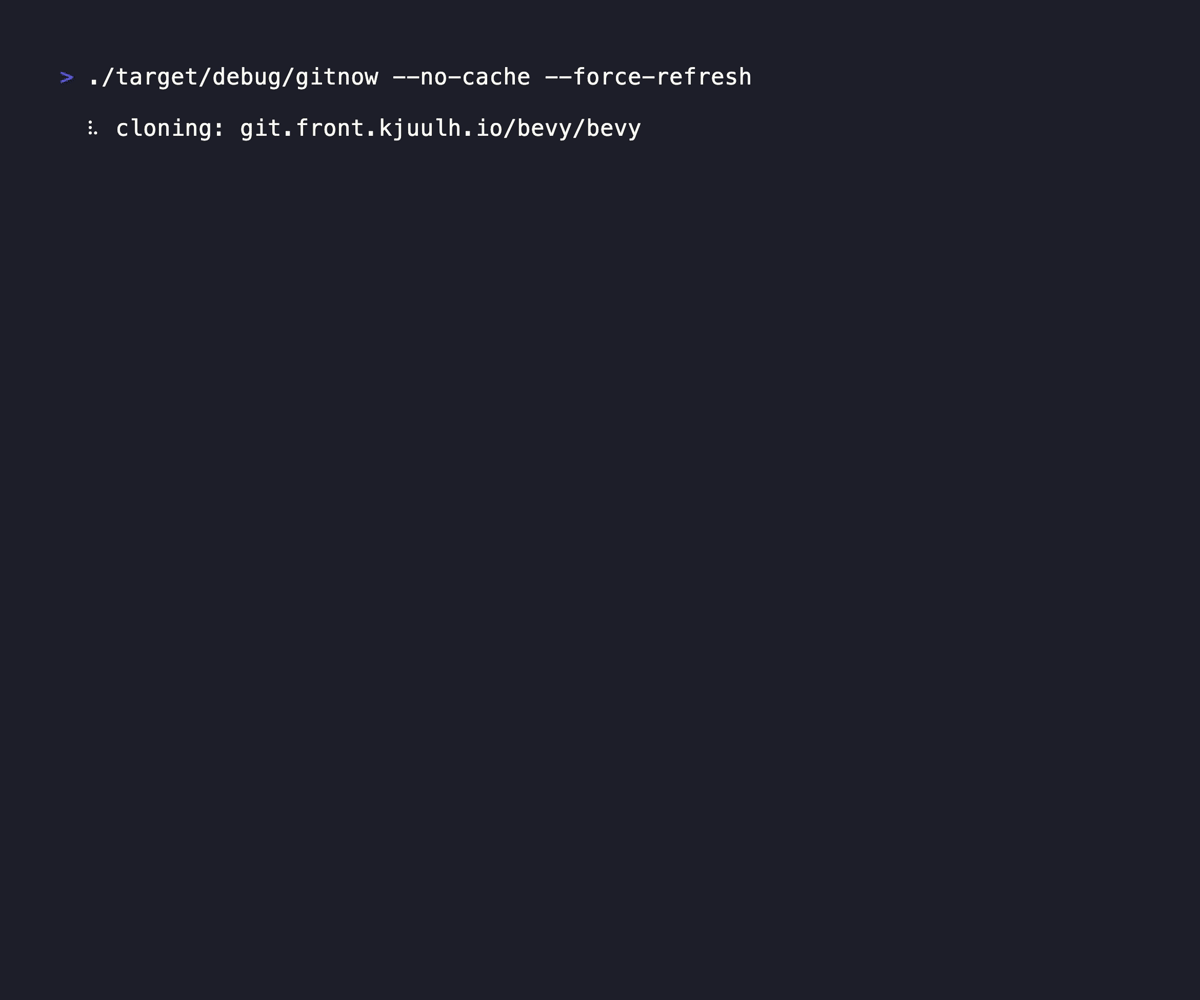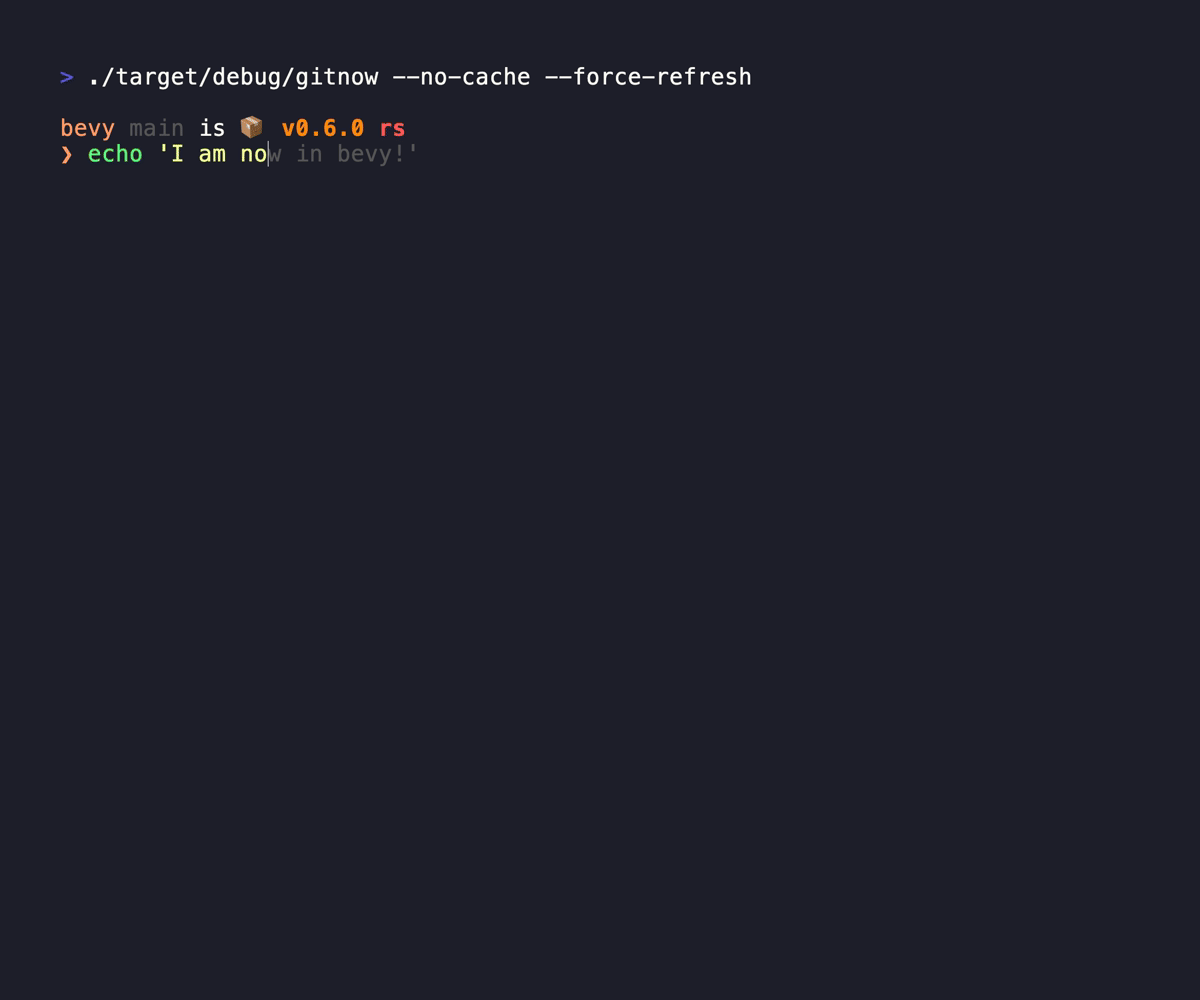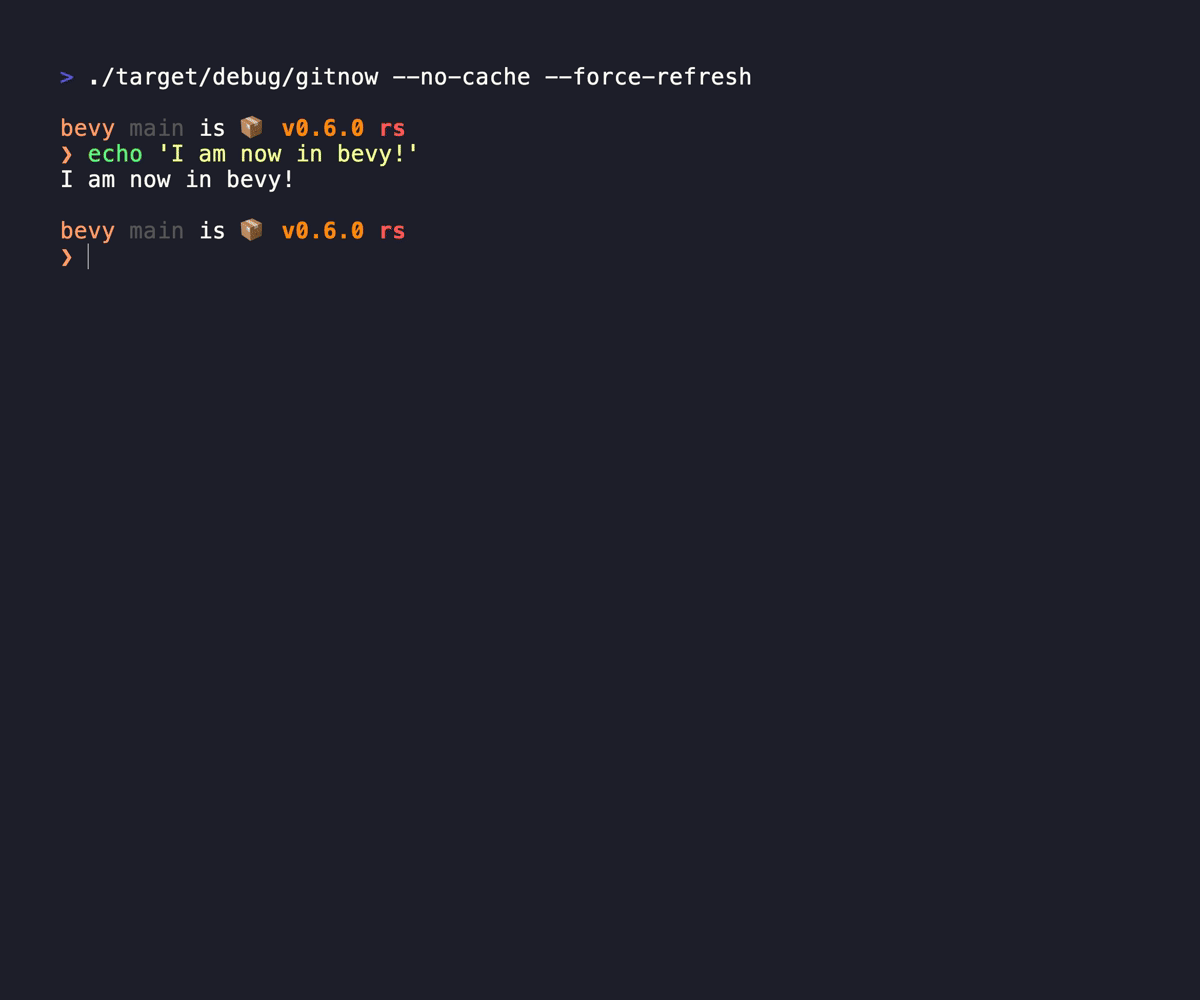
link: https://git.kjuulh.io/kjuulh/gitnow or website
I even have it aliased to , so I normally just type , and I can be in any of my subscribed codebases in a second. Love it, it has seen a ton of mileage already. 3.5k on my personal machine and 2.5k on my work laptop since march 2025.
Noil
Pronounced No oil. Not because I hate oil, but as you'll see later, I've just started to namespace a lot of my things with no as a prefix.
Noil is a terminal tui / file format / language, that emulates the oil.nvim but makes it independent of any editor. As such it loses a bit of ergonomics, which I probably could fix. But overall it suits its needs just fine as is.
The idea behind noil is that you can have a file explorer as just a text file in your editor. This on first look seems unergonomic, as there is a reason we've got the classic file-tree explorer in normal editors. However, noil makes it super easy to make a certain type of change.
Search and replace, adding files, deleting files etc. Can all be done using the commands you're familiar with, everything is just text in a normal file
Typing noil edit .
gives me a text file like so using my preferred $EDITOR
... removed for brevity
fvok : ./content/posts/2024-09-24-your-companys-superpower_1.md
fqfa : ./content/posts/2026-01-20-projects-of-2025.md
... removed for brevity
What you'll see is this post right here, it has a <hash> : <file>
the hash is as short as possible, meaning that I can a hash for each file, and calculate the shortest possible prefix and only display that, because the hash is the index, and how you do certain types of operations
DELETE fqfa : ./content/posts/2026-01-20-projects-of-2025.md
would delete.
fqfa : ./content/posts/2026-01-20-projects-of-2025.md
MOVE fqfa : ./content/posts/2026-01-20-projects-of-2030.md
To move you copy the line and rename etc. It should be noted that the hash is just an initial identifier, you can change it if you want.
some-text : ./content/posts/2026-01-20-projects-of-2025.md
COPY some-text : ./content/posts/2026-01-20-projects-of-2030.md
Is just as valid as the initial hash. What was fun about this project is that I created a tree-sitter module and my first formatter for it. So when I use this in my editor I get opinionated formatting and nice colors.
I don't use it a lot, but when I do need it, it is often because I've got a task that is annoying to solve without some kind of bulk file editor.
Notunnel & Voidpin
For all personal projects I often do them from my sofa, but remote into my workstations, I run everything in a terminal using zellij. I use a project I developed called voidpin to send clipboard across ssh sessions, as well as notunnel. Which allows me to setup a reverse proxy across nodes using cloudflare's pingora.
Basically I've got a small script on my laptop called dev
when executed it will start a voidpin and notunnel server. It will obtain some ports and ips.
It then starts a mosh zellij session on the remote machine and injects environment variables for voidpin and notunnel to be useful. For example this blog post I am running this in preview, and my local port is localhost:8000, but I cannot reach that from my laptop because it is on my workstation. So in a new tap I just run notunnel open 8000 and now on my mac it will bind these ports together, so I can now open localhost:8000 on my machine and see sites or use grpc / apis etc whatever I need from my local machine.
voidpin does the same but for clipboards, so I've set up zellij and helix (my editor) to output to voidpin on selections. In case there is no injected variables, it simply default to the built in cli clipboard (pbcopy/paste or wl-copy/paste).
I basically haven't had to touch them since I built em, and they work quite nicely. I would like raw tcp to work over notunnel as well as a dedicated wireguard tunnel / ssh tunnel. But that is planned for 2026, where I build out nocontrol below for possibly a fully fledged rust development platform for my personal homelab.
Services
I've built a few services that I use in various stages. These are often larger projects, in 2025 I didn't have too many of them. In fact I only had one really big project in the works.
Forest
Forest is a tool that allows an organisation to curate their development stack to exactly what they need. Think a combination of tools such as mise (asdf) with github actions and some kind of release agent.
It combines these tools into one tool, it doesn't replace them, but rather it allows organisations to share their config and build true golden paths for development. It is the only reason I can have many projects myself, and why at a past company we had shuttle and their release manager.
I had previous iterations of these for my personal stack, cuddle and flux-releaser
But as I started a new company I saw the need for a tool similar to shuttle, but wanted something a bit more unified with releasing in mind.
As such forest was born. It doesn't have nice documentation yet, or other important features for a full rollout.
What it does, is to allow an organisation to split up their platform tools and scripts into components. These components can be orchestrated such that the only thing developers need to think about is shipping code!
Basically just having a forest.cue file in the root of your repo and a small hook in your CI will allow a fully fledged ci pipeline, with company best-practices for deployment and so on. Eliminating terraform sprawl, complex kubernetes manifests, wasted resources, as well as getting security features easily rolled out.
project: name: "service-example"
_destinationTypes: {
kubernetes: "forest/kubernetes@1"
terraform: "forest/terraform@1"
}
dependencies: {
"forest/deployment": version: "v0.1.0"
"my-org/rust-persistent-service": path: "v0.1.0"
}
forest: deployment: enabled: true
"my-org": "rust-persistent-service": {
env: {
dev: {
destinations: [
{destination: "k8s.*", type: _destinationTypes.kubernetes},
{destination: "eu-west-1.*", type: _destinationTypes.terraform},
]
}
prod: {
destinations: [
{destination: "k8s.*", type: _destinationTypes.kubernetes},
{destination: "eu-west-1.*", type: _destinationTypes.terraform},
]
config: {
replicas: 10
environment: [{key: "RUST_LOG", value: "info"}]
}
}}
config: {
name: "service-example"
ports: [
{name: "external", port: 3000, external: true},
{name: "internal", port: 3001},
{name: "grpc_external", port: 4000, external: true, subdomain: "grpc"},
{name: "grpc_internal", port: 4001},
]
environment: [
{key: "RUST_LOG", value: "my_service=debug,info"},
]
}
}
commands: dev: ["cargo run"]
The config above doesn't actually need to be as large as it is, it is mostly to show the various levels of overrides possible, but simply having this single config allows everything a service needs to be deployed. Including the project being packaged into a docker image, having both terraform and kubernetes as a release target, the various differences between environments and destinations.
Overall I am really happy with the direction of the project, it needs a few weeks of full-time work to be fully-ready. But already it just feels right.
A few features it has:
- Allows sharing scripts like mise
forest run dev, and if multiple upstream commands provide commands, it can have fully-qualified namesforest run # fuzzy choose commandorforest run my-org@v0.1.0:dev - A release manager built in. Ship artifacts using
forest release preparepackages artifacts into deployment,forest release annotateproduce the forge / ci / local specific metadata also gives back the release intent that you can then choose to act on, or have auto-released if setup. Lastlyforest releasewhich allows you to choose a release-intent to release. Releasing will run your setup for each of the destinations and environment you've provided in a matrix. A single project can have a single logical env it releases to at once, as well as many destinations, like kubernetes clusters, aws accounts / regions / ecs clusters etc. - Templating for ownership: forest provides a lookup that can be used to assign ownership of resources
This was really fun to develop, and during development I was experimenting with claude, but had to throw away what it produced simply because it was so shit. I've since learned to work with claude to produce good quality work. But Claude is still quite bad at new development, and I've yet to seen otherwise even now using 4.5 Opus in 2026. It is amazing at following patterns, but garbage at new development that actually has to be maintained.
During the project I also explored a variety of modern human write-able configuration languages. The default was basically yaml / toml. Especially yaml is just amazing for this exact use-case, but just lacks tooling to be great.
I ended up exploring kuddle, nickel, Dhall, cuelang, ron and lua. I ended up liking cue the best, if you keep it simple it is basically a good mix of golang and json. Which I like, and if you squint it looks a bit like yaml as well. It ended up fitting the project nicely, and I actually still support all the other file formats, as they all just transpile into a common serde format (except for Lua, I think I removed that).
Winning over yaml was surprisingly hard, and even with cue I think it loses some in readability, but makes up for it in tooling / potential and ergonomics.
Nostore
This was a project that isn't ever intending to see production. It is the basics of what a mix between NATS and Warpstream (kafka) would look like. Basically I wanted to experiment with a diskless message queue, using simpler clients than what kubernetes requires.
I did achieve that goal and have found more gains since this was published. I basically ended the project as I achieved what I wanted, but also that developing it into a full project would take too much time and finagling. I'll definitely continue on this path in the future, but for now it is on ice.
During ingest it could handle 500k messages a second at a uniform 1-200KiB payload size. It was too much for my home network, as I've only got 1GB ethernet in the house, so using local sockets it could do as much throughput as I could throw at it pretty much.
Again not really documented.
Libraries
I like to explore various angles for libraries, we're continuing the namespacing, these are the most recently ones created.
Nocontrol
I like kubernetes, I don't like maintaining it though. Nocontrol brings the strength of kubernetes controllers and manifests into Rust, and only ever Rust. It is basically a library that allows you to write reconcilers around maintained resources that can be allocated to certain rust processes in a decentralized manner.
As opposed to kubernetes Nocontrol is lease based. This is as opposed to the strong consistency raft based kubernetes control plane. What this in practice means is that you can have as few or as many nocontrol nodes as you want. Each of them simply check out / steal resources they can get ahold of. This requires a backing store, currently only postgresql is implemented, but adding others are easy ;). I just don't have a need for other types of databases.
This is a big change, and as such Nocontrol relies on actor based semantics (supervisors) to implement certain logic, whereas it would be easier in kubernetes to distribute this work.
Basically to achieve a Deployment setup.
#[derive(Clone, Serialize, Deserialize)]
pub enum Specifications {
Deployment(DeploymentManifest),
Pod(PodManifest),
}
A spec is defined, the above is similar to how a deployment / pod operator would work.
You then setup an operator that handles reconciliation of resources, making sure they stay in the desired state
impl Operator for MyOperator {
type Specifications = Specifications;
type Error = anyhow::Error;
async fn reconcile(
&self,
manifest_state: &mut ManifestState<Specifications>,
) -> anyhow::Result<Action> {
todo!()
}
// A few extra methods to optionally implement
// async fn on_lease_lost() -> ...
// async fn on_error() -> ...
}
To develop a deployment operator, you would simply have a resource for the deployment, the deployment would then in turn using the control_plane api create / maintain resources for the pods. If the deployment notices there are too few, it will add more resources, and if there are too many it will take them away.
Simple as that, it isn't perfect and of course doesn't offer all the use-cases of kubernetes. It is still quite barebones, and I plan to add more to it. Because what I actually want to solve is not deployments at all, but rather a way to distribute data pipelines across many nodes.
I built this spec for my current schema applier at work
metadata:
name: experiences-core-events-event-createdv1
spec:
kind: StreamingIngest
state: Running
config:
schema_type: Protobuf
schema: | # proto
syntax = "proto3";
package dynamo.experiences_core.events.event.createdv1.v1;
import "canopy/options.proto";
message EventCreatedV1 {
option (canopy.topic) = "experiences-core.events.event.CreatedV1";
// .. removed for brevity
map<string, string> canopy_metadata = 9;
}
proto_path: dynamo/experiences-core/events/event/createdv1/v1/schema.proto
proto_package: dynamo.experiences_core.events.event.createdv1.v1.EventCreatedV1
input_table: schema__experiences_core_events_event_createdv1
topic: experiences-core.events.event.CreatedV1
environment: production
input_topic: canopy.product.dynamo.enriched.{{ environment }}.{{ key }}
output_topic: canopy.product.dynamo.structured.{{ environment }}.{{ key }}
This simply always make sure that a pod handles a pipeline, it can even have metadata for stored offsets and more for kafka. I like it, and it works quite well. I got claude to build a small tui like k9s for it, which is quite nifty, such that I can change the manifests at runtime using apis. This for example allows me to trigger a backfill of data etc.
link: nocontrol
However, I needed something to actually run the jobs, and my existing tools didn't cut it. So next up is how I run the pipelines
Noprocess
Noprocess is basically Rust tokio tasks as processes. It allows me a shared registry where I can start, stop, kill processes on demand. This is a way to ensure I always only run one process at once per name, catch failed processes and more.
It allows graceful stopping and killing (SIGINT / SIGKILL) in terms of tokio tasks, without being too disruptive, and fairly ergonomic to work with.
The above nocontrol uses noprocess kind of like how you'd use a docker client. We basically just spawn work that we need to spawn, and kill it / let it crash if required.
To me in combination it brings parts of what makes Erlang / Elixir great into what I like about Kubernetes.
Because tokio tasks are so lightweight, it can handle millions of tasks at once, though probably not recommended, and not what it was developed for. It is a little slow (single lock) in spawning tasks, and I intend to keep it that way to prevent misuse.

use noprocess::{Process, ProcessHandler, ProcessManager, ProcessResult};
use tokio_util::sync::CancellationToken;
struct MyPipeline;
impl ProcessHandler for MyPipeline {
async fn call(&self, cancel: CancellationToken) -> anyhow::Result<ProcessResult> {
async move {
loop {
tokio::select! {
_ = cancel.cancelled() => break,
_ = do_work() => {}
}
}
Ok(())
}
}
}
#[tokio::main]
async fn main() -> anyhow::Result<()> {
let manager = ProcessManager::new();
let id = manager.add_process(Process::new(MyPipeline)).await;
manager.start_process(&id).await?;
// Later: stop, restart, or kill
manager.stop_process(&id).await?;
Ok(())
}
Developed partially with Claude Code, it is subject to change, and I am probably gonna rip out the parts that claude made, as it made start / stopping overly complex.
Work
I won't go into too much detail here, as I will likely share more on our company blog, once I get that set up. But during last year, I set up most of our current data platform stack, using a mix of DuckDb, RisingWave and clickhouse and a bunch of custom tooling as seen above.
We're at a stage where we don't really need too much scale, so it is all about ergonomics, which is why i developed nocontrol, as that allows an LLM to for example develop schemas for first and third party data sources. As well as Fungus our data contract tool, which I will share details on at some point as well.
Conclusion
I think that is it for last year. I love developing stuff, and even if 2025 was a busy year for me, I still got a lot done which I am happy with. Not as much as I'd wanted, but looking back I did do a few projects that I like ;)
PS: I realize the post can come off as braggy, do know that I didn't replace Kubernetes, Kafka, etc. I simply developed a version of them that fits my needs, which if you do the same exercise will find out is a vastly smaller subset of features than the full project. So have fun with it, and go develop something.
Also if you'd like to develop stuff together, I've recently started rawpotion basically a community of developers building cool stuff together, I offer mentoring sessions as well for getting started in there.