Compare commits
1 Commits
main
...
91cf8024bc
| Author | SHA1 | Date | |
|---|---|---|---|
| 91cf8024bc |
@@ -8,7 +8,7 @@ edition = "2021"
|
|||||||
[dependencies]
|
[dependencies]
|
||||||
chrono = "0.4.26"
|
chrono = "0.4.26"
|
||||||
color-eyre = "0.6.2"
|
color-eyre = "0.6.2"
|
||||||
dagger-sdk = "0.18.3"
|
dagger-sdk = "0.19.0"
|
||||||
eyre = "0.6.8"
|
eyre = "0.6.8"
|
||||||
tokio = { version = "1.31.0", features = ["full"] }
|
tokio = { version = "1.31.0", features = ["full"] }
|
||||||
tokio-scoped = "0.2.0"
|
tokio-scoped = "0.2.0"
|
||||||
|
|||||||
@@ -1,188 +0,0 @@
|
|||||||
---
|
|
||||||
type: blog-post
|
|
||||||
title: "Your Company's Superpower: Platform Engineering"
|
|
||||||
description: Platform Engineering basically has two angles in the industry, either the hypefor it is overwhelming because it is the new hot thing on the block, or it isunderestimated because it just looks like operations doing software engineering.I aim with this piece of content to define why you should care about PlatformEngineering.
|
|
||||||
draft: false
|
|
||||||
date: 2024-09-25
|
|
||||||
updates:
|
|
||||||
- time: 2024-09-25
|
|
||||||
description: first iteration
|
|
||||||
tags:
|
|
||||||
- "#blog"
|
|
||||||
---
|
|
||||||
Platform Engineering basically has two angles in the industry, either the hype
|
|
||||||
for it is overwhelming because it is the new hot thing on the block, or it is
|
|
||||||
underestimated because it just looks like operations doing software engineering.
|
|
||||||
I aim with this piece of content to define why you should care about Platform
|
|
||||||
Engineering.
|
|
||||||
|
|
||||||
## Platform Engineering defined
|
|
||||||
|
|
||||||
Platform Engineering to its namesake, is the practice of engineering a platform.
|
|
||||||
Often as Software Engineers we forget what the Engineering in our titles
|
|
||||||
actually mean. Engineering means building the right thing, reliably and
|
|
||||||
securely. That we understand, but the platform is harder to define. When we
|
|
||||||
think of a Platform for a company, it is the foundation that other users within
|
|
||||||
the company utilize. An important detail here is that Platform Engineering is
|
|
||||||
not just for developers, it can be for business users, data analysts, operations
|
|
||||||
people, etc. It is basically a vehicle to make someone elses job easier within
|
|
||||||
the company.
|
|
||||||
|
|
||||||
An example of a platform to be built could be: A specific individual or team,
|
|
||||||
owning the deployment pipeline that ships software into production, the metrics
|
|
||||||
solution that is used across the company, the tool analysts interface with when
|
|
||||||
they want to query the data in the company.
|
|
||||||
|
|
||||||
These might sound mundane, and you may have a question, but hey, I could just
|
|
||||||
setup github actions, and boom, my service is now going to production. You would
|
|
||||||
be correct, Platform Engineering is taking a holistic view of the company's
|
|
||||||
portfolio of tools, and make decision based on those. Often tooling starts grass
|
|
||||||
roots, a developer is missing a feature, he/she goes and implements said
|
|
||||||
feature, they now have a pipeline to build and deploy their code. But so does
|
|
||||||
the other 15 teams in the company, and now you've got 15 bespoke solutions.
|
|
||||||
Another step would be a DevOps department, being consultants to the different
|
|
||||||
teams to have some homogeniety.
|
|
||||||
|
|
||||||
A Platform Engineering team would take those requirements; we need a build and
|
|
||||||
deployment capability across the company, lets come up with as simple solution
|
|
||||||
as possible to capture the largest amount of complexity. As such the team might
|
|
||||||
end up building a complete build pipeline, but only for Golang Services, and as
|
|
||||||
such keep the complexity around for Python Services or what have you. The
|
|
||||||
Platform Engineering team would then treat the pipeline as a product, handle
|
|
||||||
user feedback, user interviews, track data for adoption, make sure the right
|
|
||||||
features are available, etc.
|
|
||||||
|
|
||||||
The end product is that you've got a dedicated team, which can capture the
|
|
||||||
partial complexity for 15 teams, and if the product is good enough, it can be
|
|
||||||
complete, i.e. the friction between the development teams and the platform teams
|
|
||||||
is minimal. If you extrapolate this mindset, you can go from:
|
|
||||||
|
|
||||||
Here is the example of the scope of the complexity a normal organisation might
|
|
||||||
have in software products, internal to the company, but without dedicated
|
|
||||||
stewardship.
|
|
||||||
|
|
||||||
5 programming languages, 30 pipelines, 5 types of software libraries, 10
|
|
||||||
libraries pr language, 30 types of deployment, 3 clouds
|
|
||||||
|
|
||||||
`5 + 30 + 5 * 10 + 30 + 3 = 83` products spread out over the organisation
|
|
||||||
|
|
||||||
Versus a stewarded Platform
|
|
||||||
|
|
||||||
1 programming language, 1 pipeline, 10 libraries, 1 deployment, 1 cloud
|
|
||||||
|
|
||||||
`1 + 1 + 10 + 1 + 1 = 14` products dedicated to a specialized team
|
|
||||||
|
|
||||||
You might say, that it is inrealistic to succeed with a single programming
|
|
||||||
language, or 1 pipeline, but it can be done. It can be a long journey to get
|
|
||||||
there, and you may not want to go that far, if you've got enough people to
|
|
||||||
maintain the software. But in general, the goal of Platform Engineering in such
|
|
||||||
an organisation is to move out complexity of feature teams to let them focus on
|
|
||||||
what they're best at; building features.
|
|
||||||
|
|
||||||
As is often the case, Platform Engineers are basically Software Engineering
|
|
||||||
working in a specialized field, with specialized tooling, as such it is more
|
|
||||||
approachable to tackle familiar problems, i.e. building out a deployment
|
|
||||||
strategy for Kubernetes, AWS, whatever. But it can also be so much more. How do
|
|
||||||
SQL analysts interface with their tools, what is slowing them down, do they
|
|
||||||
achieve the quality they want from the products they rely on, are their
|
|
||||||
workflows as effecient and tight as can be? Often this isn't the case, in the
|
|
||||||
same vein as a software engineer hacking together a pipeline, and analyst might
|
|
||||||
cook up a workflow that is borderline masochism. As Platform Engineers we've got
|
|
||||||
the knowledge and tools to help shape some of the workflows and tools to fit the
|
|
||||||
needs of our users.
|
|
||||||
|
|
||||||
## Platform Engineering doesn't mean invented here
|
|
||||||
|
|
||||||
Platform Engineering can be taken to its extremes, where we basically build all
|
|
||||||
the tools from scratch, define all workflows, templates by hand, and rely on a
|
|
||||||
massive team to support said complexity. But it shouldn't be our first approach,
|
|
||||||
one of the most interesting things about Platform Engineering is the creativity
|
|
||||||
it invites. Hey, I need to build a build pipeline, what tools do I have
|
|
||||||
available, and how can I turn this into a good product and abstraction for my
|
|
||||||
users. Do I really want to provide a small layer of abstraction on top of github
|
|
||||||
actions/jenkins etc. Or will we build a turnkey solution that basically builds
|
|
||||||
our company's version of what a Golang services looks like.
|
|
||||||
|
|
||||||
Are we supposed to build the entire build pipeline software ourselves, or can we
|
|
||||||
leverage either open-source offerings, or SaaS solutions and provide a small
|
|
||||||
opinionated layer on top to make it a product internally. That is really the
|
|
||||||
goal of Platform Engineering, to think creatively about problems, such that we
|
|
||||||
can build the most reliable thing, with the lowest complexity, in the most
|
|
||||||
secure manner.
|
|
||||||
|
|
||||||
## Platform Engineering A Superpower
|
|
||||||
|
|
||||||
I gotta make up for the title, so how is Platform Engineering a superpower? Lets
|
|
||||||
say a new security requirement comes down, that you now need to calculate
|
|
||||||
software bills of materials across all of your software because you want to sell
|
|
||||||
your services to an organisation that requires that level of security. You can
|
|
||||||
basically measure your profecciency in Platform Engineering in how well you're
|
|
||||||
able to execute cross cutting concerns.
|
|
||||||
|
|
||||||
If you had 30 pipelines, for 5 languages. You'd need to basically copy
|
|
||||||
paste/modify whatever the same product to produce software bills of materials to
|
|
||||||
each and every pipeline, that may run on different types of CI systems, have
|
|
||||||
different level of compatibility with the language in question.
|
|
||||||
|
|
||||||
If you however had 1 language and 1 pipeline, across the entire fleet of
|
|
||||||
services, you could basically build the feature in the afternoon, append it to
|
|
||||||
the build pipeline, track all the builds and see that all artifacts required
|
|
||||||
were produced. With Platform Engineering you've basically transformed a
|
|
||||||
challenging multi month effort into an afternoon project.
|
|
||||||
|
|
||||||
For the first approach developer teams will also have to own the changes,
|
|
||||||
because it is their pipelines, how difficult would it be to prioritise that
|
|
||||||
across 30 teams? From experience there are always a handful that are absolutely
|
|
||||||
strapped for time, so you probably wouldn't make it in time. The second approach
|
|
||||||
is completely automated, they wouldn't even know their pipelines are producing
|
|
||||||
bills of materials. The same could be said for signing artifacts, producing
|
|
||||||
artifacts for other architectures, swapping out library internals and whatnot.
|
|
||||||
|
|
||||||
It can be extremely fulfilling work to build a project that can basically
|
|
||||||
bootstrap a service from scratch to production in minutes, without any handoff
|
|
||||||
to other teams, or requring complex manuals for actually being allowed to go in
|
|
||||||
production. As a Platform Engineering team, we can offload a lot of requirements
|
|
||||||
from teams, such they can focus on delivering value for our paying customers,
|
|
||||||
and in turn make the organisation much more nimble, scaleable and so on.
|
|
||||||
|
|
||||||
## Platform Engineering is a double edged sword
|
|
||||||
|
|
||||||
If your Platform Engineering team isn't able to build whole abstractions, which
|
|
||||||
by the way are extremely difficult to build. They will have a lot of maintenance
|
|
||||||
on their hands, if they aren't able to fulfill requirements from their
|
|
||||||
customers, the developers, analysts and so on. You might end up with a munity on
|
|
||||||
your hands. People simply going rogue, because the complexity of the platform
|
|
||||||
has increased to an almost absurd level.
|
|
||||||
|
|
||||||
This can happen and it needs to be careful considered, as engineers we should
|
|
||||||
continuously defer products to maintenance, and pick them up once offerings
|
|
||||||
become available via. open-source or proprietary software caches up with our own
|
|
||||||
abstractions.
|
|
||||||
|
|
||||||
You might build a state of the art build system one year, let it run for 5, and
|
|
||||||
suddenly it is clunky to work with, because it has been in maintenance mode for
|
|
||||||
years, but you may discover that an open-source tool has matured that is able to
|
|
||||||
fill some of those requirements you had, because you're fully in control of the
|
|
||||||
platform you might even be able to swap out the "engine" with a less complex
|
|
||||||
one, and free up some maintenance budget for your team.
|
|
||||||
|
|
||||||
I'll discuss when you should make those decision and what they look like in
|
|
||||||
another piece of content.
|
|
||||||
|
|
||||||
## Teams require help to be in control of their software
|
|
||||||
|
|
||||||
At the end of the day, feature teams should still be fully responsible for their
|
|
||||||
products, including the operations. So as a Platform Team you've got to
|
|
||||||
carefully consider how you allow them to be in control. Do you send back all the
|
|
||||||
right signals for them to be in control? Do they know much many applications
|
|
||||||
they're running, how much CPU, memory they're using. What is their SQL latency,
|
|
||||||
when did they deploy, which version is deployed, how are their gRPC latencies,
|
|
||||||
what is the HTTP Error rate.
|
|
||||||
|
|
||||||
Again you can treat these as products, it doens't have to be fancy, but it takes
|
|
||||||
a long time to get this right, and as you build abstractions on top of products,
|
|
||||||
you'll continuously see that as services demand more of the platform that more
|
|
||||||
and more of the internals needs to be exposed, such that the feature teams can
|
|
||||||
engineer their services to the implicit requirements of the platform. I.e. they
|
|
||||||
might need to tune memory settings, connection pools, http authentication, which
|
|
||||||
ports are open. To what the platform expects.
|
|
||||||
42
content/posts/2025-06-02-are-we-general-purpose-yet.md
Normal file
42
content/posts/2025-06-02-are-we-general-purpose-yet.md
Normal file
@@ -0,0 +1,42 @@
|
|||||||
|
---
|
||||||
|
type: blog-post
|
||||||
|
title: "Rust: Are we general purpose yet?"
|
||||||
|
description:
|
||||||
|
draft: true
|
||||||
|
date: 2025-06-02
|
||||||
|
updates:
|
||||||
|
- time: 2025-06-02
|
||||||
|
description: first iteration
|
||||||
|
tags:
|
||||||
|
- "#blog"
|
||||||
|
- "#rust"
|
||||||
|
---
|
||||||
|
|
||||||
|
Rust has been steadily improving over the past few years, we've gotten more
|
||||||
|
complete support for async, still not fully there yet, but we're getting there.
|
||||||
|
Const generics, closures and more have also seen improvements. But all these
|
||||||
|
language features, doesn't really tell us about Rusts place in the industry, so
|
||||||
|
in this post I'll try my best to explain if I think Rust is ready for the
|
||||||
|
mainstream.
|
||||||
|
|
||||||
|
First of all lets (try) define out what general purpose means.
|
||||||
|
|
||||||
|
> In computer software, a general-purpose programming language (GPL) is a
|
||||||
|
> programming language for building software in a wide variety of application
|
||||||
|
> domains. Conversely, a domain-specific programming language (DSL) is used
|
||||||
|
> within a specific area.
|
||||||
|
|
||||||
|
[wikipedia: general purpose programming language](https://en.wikipedia.org/wiki/General-purpose_programming_language)
|
||||||
|
|
||||||
|
In laymans terms, a language that can be written to target varied use-cases,
|
||||||
|
whether they be: application development, web services, systems programming,
|
||||||
|
etc.
|
||||||
|
|
||||||
|
My own definition also includes choice, weirdly enough. This means do people
|
||||||
|
consider _it_ a mainstream language. When they pick up a new project, do they
|
||||||
|
actively weigh Rust as a contender. And do people choose rust for these cases.
|
||||||
|
|
||||||
|
With these definitions we're not gonna end up with a yes/no situation, there is
|
||||||
|
definitely a gray zone, a large one at that.
|
||||||
|
|
||||||
|
I'll be doing a fairly biased
|
||||||
@@ -1,384 +0,0 @@
|
|||||||
---
|
|
||||||
type: blog-post
|
|
||||||
title: "Projects of 2025"
|
|
||||||
description:
|
|
||||||
draft: false
|
|
||||||
date: 2026-01-20
|
|
||||||
updates:
|
|
||||||
- time: 2026-01-20
|
|
||||||
description: first iteration
|
|
||||||
tags:
|
|
||||||
- "#blog"
|
|
||||||
- "#rust"
|
|
||||||
---
|
|
||||||
|
|
||||||
We're now well into 2026, and it has been a while since I've written a blog post. So why not start off with a little retrospective? 2025 was a year of change for me, and initially I wasn't going to write this post, as I've been busy with life and work; started new job in a start-up, and moved into my first house (on the same day...) planning has never been my strong suit.
|
|
||||||
|
|
||||||
In this post I am going over a few projects I've written for myself, and work, often because I have difficulty separating the two. I simply like to produce stuff that is useful, and that can often be used at work as well.
|
|
||||||
|
|
||||||
As it has been a while since I've posted anything, and if you've read previous posts of mine, you might be surprised to know that I am now working in the data space, and that is where my focus has been since end 2024 until now.
|
|
||||||
|
|
||||||
Let's jump straight into the projects shall we.
|
|
||||||
|
|
||||||
> I should mention that some of the tools were developed using Claude. But was mostly used for refactorings and writing up documentation etc. I don't actually like many of the parts that were developed using Claude, so I am planning on ripping them out, and only using Claude at the "edge" of the projects
|
|
||||||
|
|
||||||
## Personal Productivity
|
|
||||||
|
|
||||||
This is a bunch of tools I've created to expand my workflow, I live on the terminal pretty much always, so these are convenience tools to help me have more fun, be more efficient etc.
|
|
||||||
|
|
||||||
### GitNow
|
|
||||||
|
|
||||||
```
|
|
||||||
[▮▮▮▮▮▮▮▮▮▮] 7939 hx
|
|
||||||
[▮▮▮▮▮▮ ] 5046 cargo run
|
|
||||||
[▮▮▮▮▮ ] 4278 jj
|
|
||||||
[▮▮▮▮▮ ] 4202 gca
|
|
||||||
[▮▮▮▮ ] 3567 ,
|
|
||||||
[▮▮▮ ] 2834 ranger
|
|
||||||
[▮▮ ] 2321 gp
|
|
||||||
[▮▮ ] 2113 m
|
|
||||||
[▮▮ ] 1902 gs
|
|
||||||
[▮▮ ] 1888 rg
|
|
||||||
```
|
|
||||||
<small>history of commands I've run in 2025 on my personal pc</small>
|
|
||||||
|
|
||||||
I use ~git~ (jujutsu) a lot, and have a lot of projects I work on, both at work and personally. 105 personal project checked out, 244 for work. Zoxide is a great tool to use to move between them, but often I end up in this situation.
|
|
||||||
|
|
||||||
1. Let me go to this project
|
|
||||||
2. Dang I don't have it checked out
|
|
||||||
3. Go to github or my own git.kjuulh.io gitea instance
|
|
||||||
4. Search for project
|
|
||||||
5. Click copy ssh
|
|
||||||
6. cd into ~/git/git.kjuulh.io/kjuulh and run git clone `<repo>`
|
|
||||||
7. cd `<repo>`
|
|
||||||
|
|
||||||
Often you could just clone directly, but often when I don't have it checked out, I am not 100% sure about the name of the repo.
|
|
||||||
|
|
||||||
That is why I built GitNow. Seriously it is a small tool, but it brings me joy every time I use it, even if it is brief (as it should be)
|
|
||||||
|
|
||||||
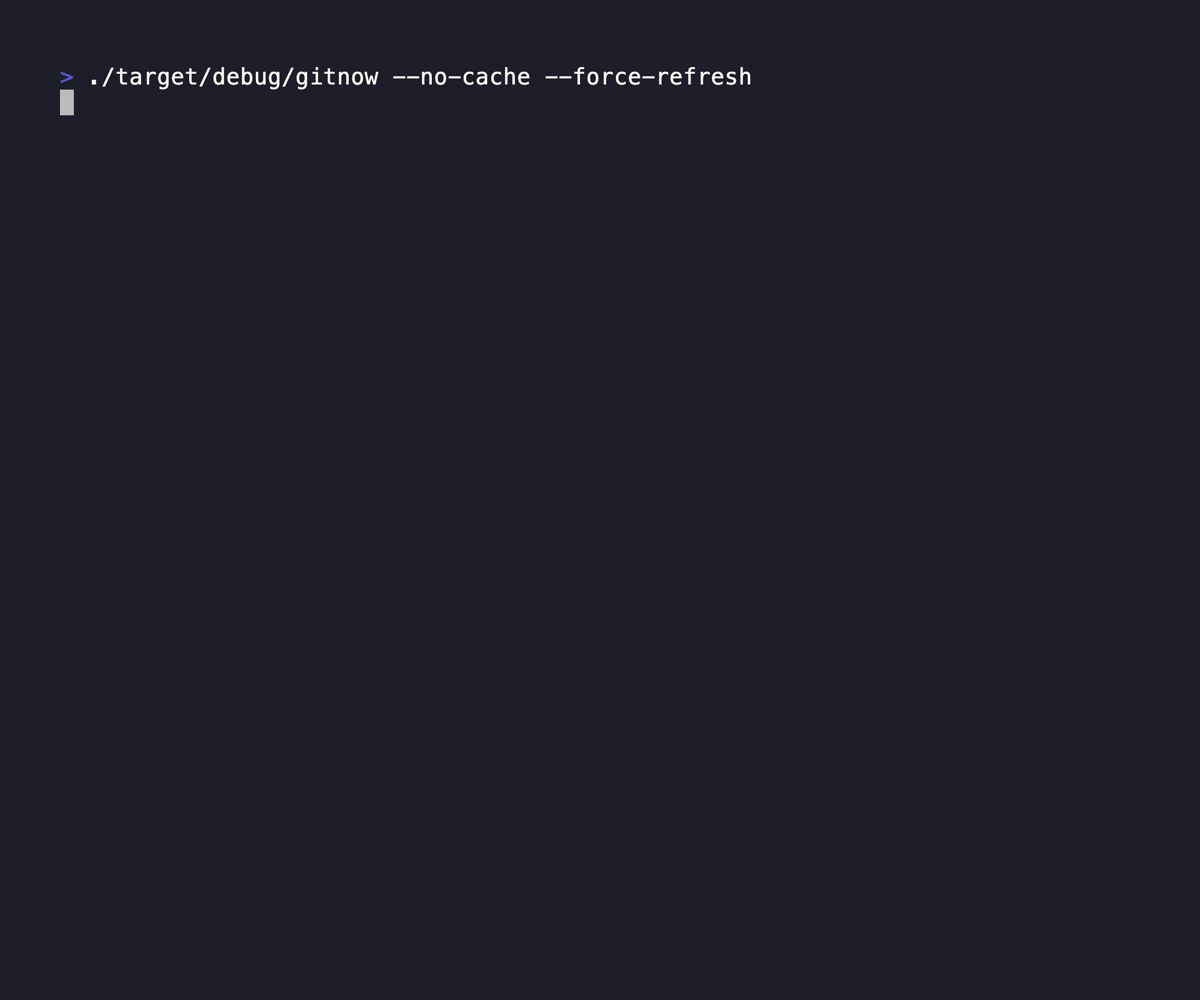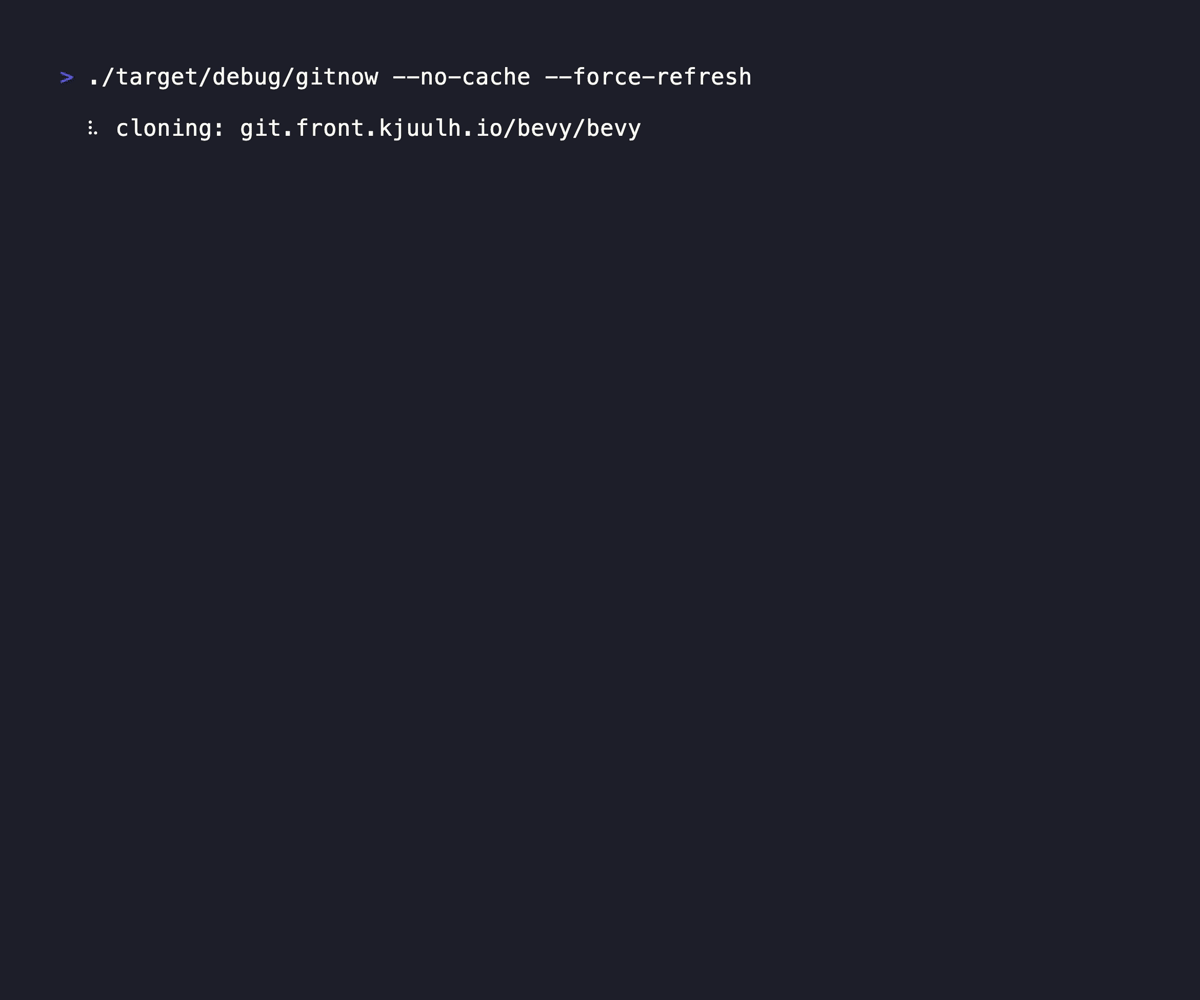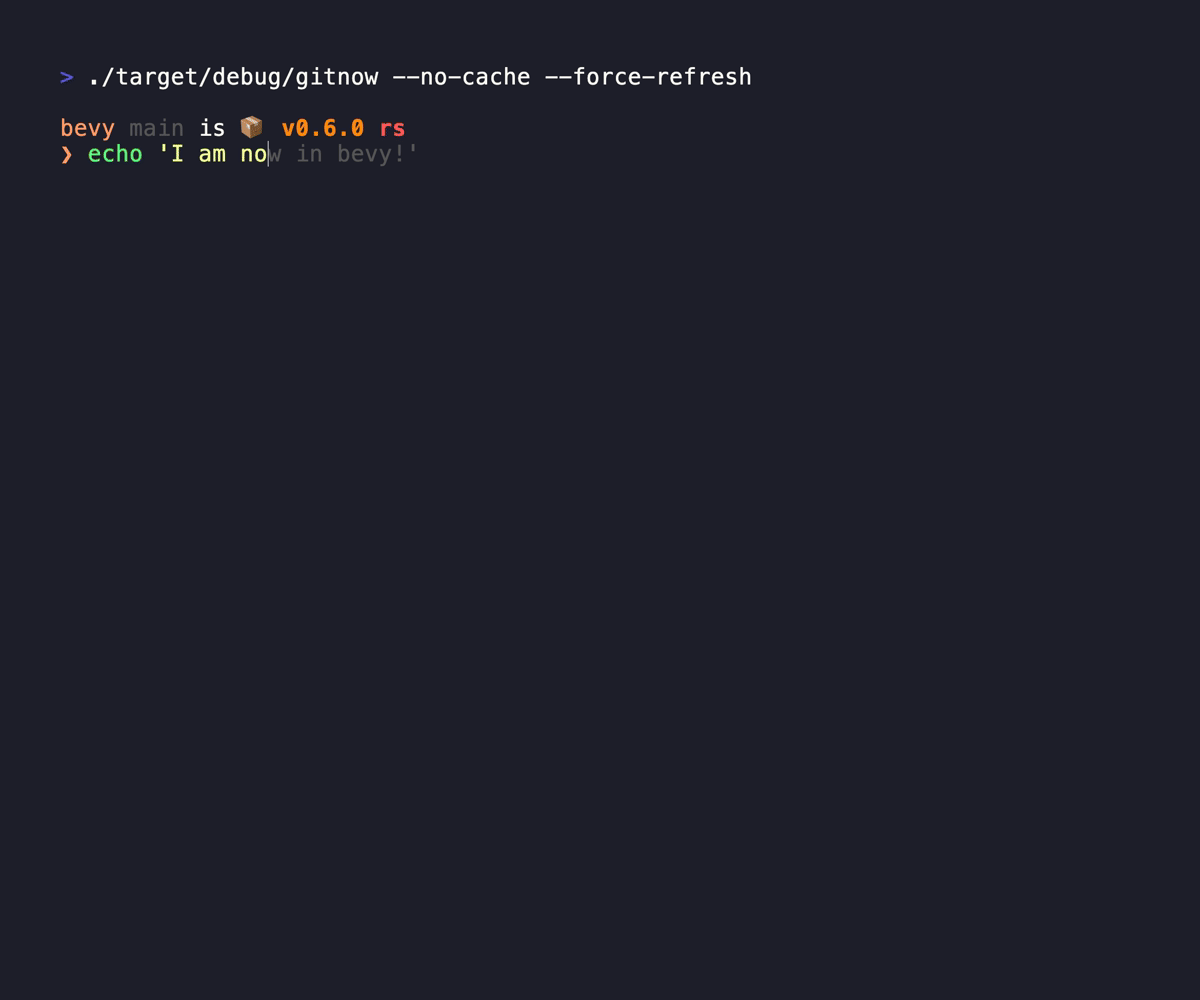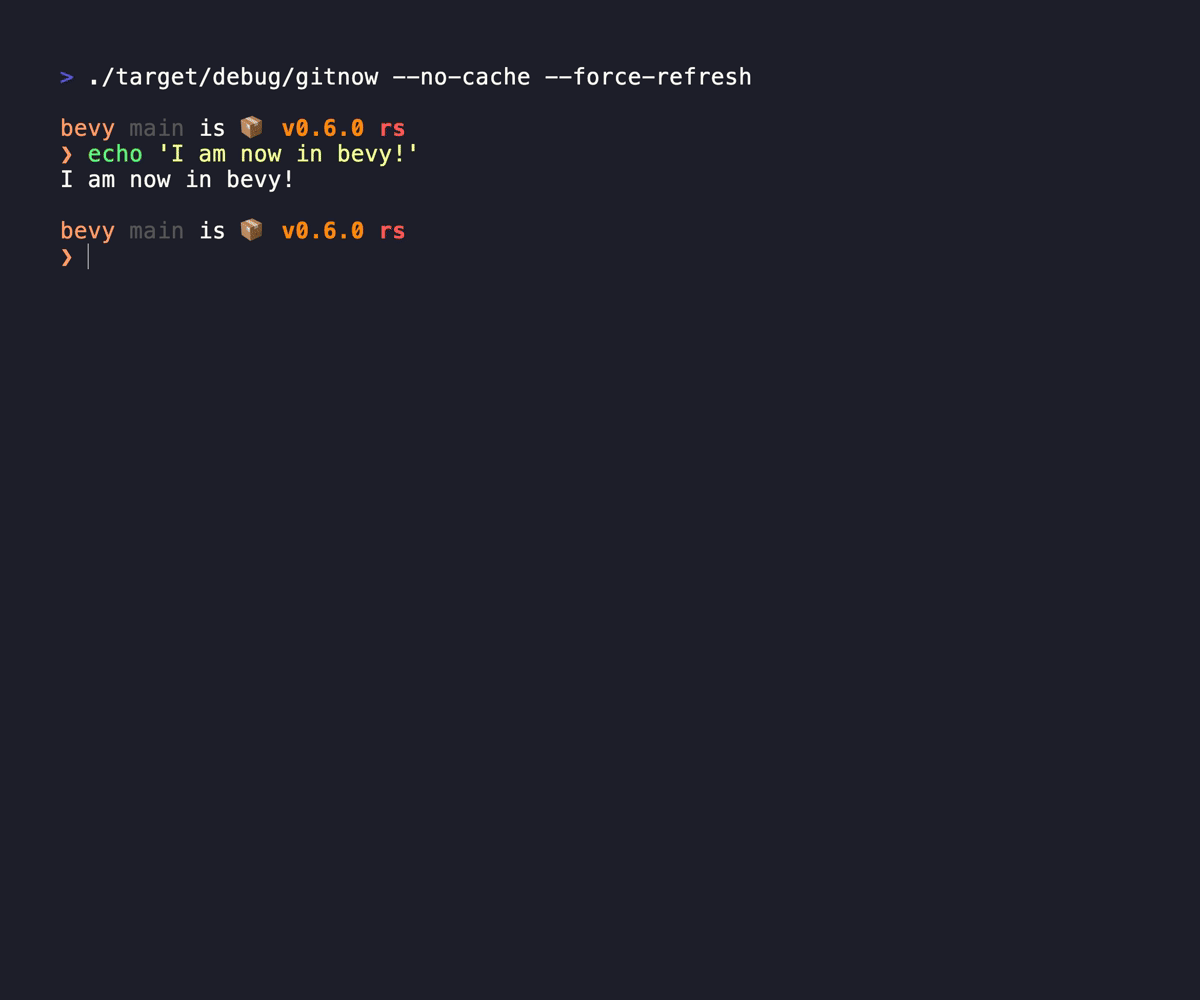
GitNow allows me to quickly fuzzy search repos, move the current console to the placement, or clone the sucker. It brings at task down from 30 seconds down to 2 seconds, and it does double duty simply because it just allows me to move between repos if I've already got it down, replacing zoxide for me. It caches the responses from the forges you subscribe to, so it doesn't have to wait for any network calls, and quietly updates the cache in the background.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
link: [https://git.kjuulh.io/kjuulh/gitnow](https://git.kjuulh.io/kjuulh/gitnow) or [website](https://gitnow.kjuulh.io/)
|
|
||||||
|
|
||||||
I even have it aliased to `,` so I normally just type `,` and I can be in any of my subscribed codebases in a second. Love it, it has seen a ton of mileage already. 3.5k on my personal machine and 2.5k on my work laptop since march 2025.
|
|
||||||
|
|
||||||
## Noil
|
|
||||||
|
|
||||||
Pronounced No oil. Not because I hate oil, but as you'll see later, I've just started to namespace a lot of my things with no as a prefix.
|
|
||||||
|
|
||||||
Noil is a terminal tui / file format / language, that emulates the [oil.nvim](https://github.com/stevearc/oil.nvim) but makes it independent of any editor. As such it loses a bit of ergonomics, which I probably could fix. But overall it suits its needs just fine as is.
|
|
||||||
|
|
||||||
The idea behind noil is that you can have a file explorer as just a text file in your editor. This on first look seems unergonomic, as there is a reason we've got the classic file-tree explorer in normal editors. However, noil makes it super easy to make a certain type of change.
|
|
||||||
|
|
||||||
Search and replace, adding files, deleting files etc. Can all be done using the commands you're familiar with, everything is just text in a normal file
|
|
||||||
|
|
||||||
Typing `noil edit .`
|
|
||||||
|
|
||||||
gives me a text file like so using my preferred `$EDITOR`
|
|
||||||
|
|
||||||
```
|
|
||||||
... removed for brevity
|
|
||||||
|
|
||||||
fvok : ./content/posts/2024-09-24-your-companys-superpower_1.md
|
|
||||||
fqfa : ./content/posts/2026-01-20-projects-of-2025.md
|
|
||||||
|
|
||||||
... removed for brevity
|
|
||||||
```
|
|
||||||
|
|
||||||
What you'll see is this post right here, it has a `<hash> : <file>`
|
|
||||||
|
|
||||||
the hash is as short as possible, meaning that I can a hash for each file, and calculate the shortest possible prefix and only display that, because the hash is the index, and how you do certain types of operations
|
|
||||||
|
|
||||||
```
|
|
||||||
DELETE fqfa : ./content/posts/2026-01-20-projects-of-2025.md
|
|
||||||
```
|
|
||||||
|
|
||||||
would delete.
|
|
||||||
|
|
||||||
```
|
|
||||||
fqfa : ./content/posts/2026-01-20-projects-of-2025.md
|
|
||||||
MOVE fqfa : ./content/posts/2026-01-20-projects-of-2030.md
|
|
||||||
```
|
|
||||||
|
|
||||||
To move you copy the line and rename etc. It should be noted that the hash is just an initial identifier, you can change it if you want.
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
some-text : ./content/posts/2026-01-20-projects-of-2025.md
|
|
||||||
COPY some-text : ./content/posts/2026-01-20-projects-of-2030.md
|
|
||||||
```
|
|
||||||
|
|
||||||
Is just as valid as the initial hash. What was fun about this project is that I created a tree-sitter module and my first formatter for it. So when I use this in my editor I get opinionated formatting and nice colors.
|
|
||||||
|
|
||||||
I don't use it a lot, but when I do need it, it is often because I've got a task that is annoying to solve without some kind of bulk file editor.
|
|
||||||
|
|
||||||
[noil](https://noil.kjuulh.io/)
|
|
||||||
|
|
||||||
### Notunnel & Voidpin
|
|
||||||
|
|
||||||
For all personal projects I often do them from my sofa, but remote into my workstations, I run everything in a terminal using zellij. I use a project I developed called voidpin to send clipboard across ssh sessions, as well as notunnel. Which allows me to setup a reverse proxy across nodes using cloudflare's pingora.
|
|
||||||
|
|
||||||
Basically I've got a small script on my laptop called `dev`
|
|
||||||
|
|
||||||
when executed it will start a voidpin and notunnel server. It will obtain some ports and ips.
|
|
||||||
|
|
||||||
It then starts a mosh zellij session on the remote machine and injects environment variables for voidpin and notunnel to be useful. For example this blog post I am running this in preview, and my local port is localhost:8000, but I cannot reach that from my laptop because it is on my workstation. So in a new tap I just run notunnel open 8000 and now on my mac it will bind these ports together, so I can now open localhost:8000 on my machine and see sites or use grpc / apis etc whatever I need from my local machine.
|
|
||||||
|
|
||||||
voidpin does the same but for clipboards, so I've set up zellij and helix (my editor) to output to voidpin on selections. In case there is no injected variables, it simply default to the built in cli clipboard (pbcopy/paste or wl-copy/paste).
|
|
||||||
|
|
||||||
I basically haven't had to touch them since I built em, and they work quite nicely. I would like raw tcp to work over notunnel as well as a dedicated wireguard tunnel / ssh tunnel. But that is planned for 2026, where I build out nocontrol below for possibly a fully fledged rust development platform for my personal homelab.
|
|
||||||
|
|
||||||
## Services
|
|
||||||
|
|
||||||
I've built a few services that I use in various stages. These are often larger projects, in 2025 I didn't have too many of them. In fact I only had one really big project in the works.
|
|
||||||
|
|
||||||
### Forest
|
|
||||||
|
|
||||||
Forest is a tool that allows an organisation to curate their development stack to exactly what they need. Think a combination of tools such as mise (asdf) with github actions and some kind of release agent.
|
|
||||||
|
|
||||||
It combines these tools into one tool, it doesn't replace them, but rather it allows organisations to share their config and build true golden paths for development. It is the only reason I can have many projects myself, and why at a past company we had [shuttle](https://github.com/lunar/shuttle) and their release manager.
|
|
||||||
|
|
||||||
I had previous iterations of these for my personal stack, [cuddle](https://git.kjuulh.io/kjuulh/cuddle) and [flux-releaser](https://git.kjuulh.io/kjuulh/flux-releaser)
|
|
||||||
|
|
||||||
But as I started a new company I saw the need for a tool similar to shuttle, but wanted something a bit more unified with releasing in mind.
|
|
||||||
|
|
||||||
As such [forest](https://git.kjuulh.io/kjuulh/forest) was born. It doesn't have nice documentation yet, or other important features for a full rollout.
|
|
||||||
|
|
||||||
What it does, is to allow an organisation to split up their platform tools and scripts into components. These components can be orchestrated such that the only thing developers need to think about is shipping code!
|
|
||||||
|
|
||||||
Basically just having a `forest.cue` file in the root of your repo and a small hook in your CI will allow a fully fledged ci pipeline, with company best-practices for deployment and so on. Eliminating terraform sprawl, complex kubernetes manifests, wasted resources, as well as getting security features easily rolled out.
|
|
||||||
|
|
||||||
```cue
|
|
||||||
project: name: "service-example"
|
|
||||||
|
|
||||||
_destinationTypes: {
|
|
||||||
kubernetes: "forest/kubernetes@1"
|
|
||||||
terraform: "forest/terraform@1"
|
|
||||||
}
|
|
||||||
|
|
||||||
dependencies: {
|
|
||||||
"forest/deployment": version: "v0.1.0"
|
|
||||||
"my-org/rust-persistent-service": path: "v0.1.0"
|
|
||||||
}
|
|
||||||
|
|
||||||
forest: deployment: enabled: true
|
|
||||||
|
|
||||||
"my-org": "rust-persistent-service": {
|
|
||||||
env: {
|
|
||||||
dev: {
|
|
||||||
destinations: [
|
|
||||||
{destination: "k8s.*", type: _destinationTypes.kubernetes},
|
|
||||||
{destination: "eu-west-1.*", type: _destinationTypes.terraform},
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
prod: {
|
|
||||||
destinations: [
|
|
||||||
{destination: "k8s.*", type: _destinationTypes.kubernetes},
|
|
||||||
{destination: "eu-west-1.*", type: _destinationTypes.terraform},
|
|
||||||
]
|
|
||||||
config: {
|
|
||||||
replicas: 10
|
|
||||||
environment: [{key: "RUST_LOG", value: "info"}]
|
|
||||||
}
|
|
||||||
}}
|
|
||||||
|
|
||||||
config: {
|
|
||||||
name: "service-example"
|
|
||||||
ports: [
|
|
||||||
{name: "external", port: 3000, external: true},
|
|
||||||
{name: "internal", port: 3001},
|
|
||||||
{name: "grpc_external", port: 4000, external: true, subdomain: "grpc"},
|
|
||||||
{name: "grpc_internal", port: 4001},
|
|
||||||
]
|
|
||||||
environment: [
|
|
||||||
{key: "RUST_LOG", value: "my_service=debug,info"},
|
|
||||||
]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
commands: dev: ["cargo run"]
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
The config above doesn't actually need to be as large as it is, it is mostly to show the various levels of overrides possible, but simply having this single config allows everything a service needs to be deployed. Including the project being packaged into a docker image, having both terraform and kubernetes as a release target, the various differences between environments and destinations.
|
|
||||||
|
|
||||||
Overall I am really happy with the direction of the project, it needs a few weeks of full-time work to be fully-ready. But already it just feels right.
|
|
||||||
|
|
||||||
A few features it has:
|
|
||||||
|
|
||||||
1. Allows sharing scripts like mise `forest run dev`, and if multiple upstream commands provide commands, it can have fully-qualified names `forest run # fuzzy choose command` or `forest run my-org@v0.1.0:dev`
|
|
||||||
2. A release manager built in. Ship artifacts using `forest release prepare` packages artifacts into deployment, `forest release annotate` produce the forge / ci / local specific metadata also gives back the release intent that you can then choose to act on, or have auto-released if setup. Lastly `forest release` which allows you to choose a release-intent to release. Releasing will run your setup for each of the destinations and environment you've provided in a matrix. A single project can have a single logical env it releases to at once, as well as many destinations, like kubernetes clusters, aws accounts / regions / ecs clusters etc.
|
|
||||||
3. Templating for ownership: forest provides a lookup that can be used to assign ownership of resources
|
|
||||||
|
|
||||||
This was really fun to develop, and during development I was experimenting with claude, but had to throw away what it produced simply because it was so shit. I've since learned to work with claude to produce good quality work. But Claude is still quite bad at new development, and I've yet to seen otherwise even now using 4.5 Opus in 2026. It is amazing at following patterns, but garbage at new development that actually has to be maintained.
|
|
||||||
|
|
||||||
During the project I also explored a variety of modern human write-able configuration languages. The default was basically yaml / toml. Especially yaml is just amazing for this exact use-case, but just lacks tooling to be great.
|
|
||||||
|
|
||||||
I ended up exploring kuddle, nickel, Dhall, cuelang, ron and lua. I ended up liking cue the best, if you keep it simple it is basically a good mix of golang and json. Which I like, and if you squint it looks a bit like yaml as well. It ended up fitting the project nicely, and I actually still support all the other file formats, as they all just transpile into a common serde format (except for Lua, I think I removed that).
|
|
||||||
|
|
||||||
Winning over yaml was surprisingly hard, and even with cue I think it loses some in readability, but makes up for it in tooling / potential and ergonomics.
|
|
||||||
|
|
||||||
### Nostore
|
|
||||||
|
|
||||||
This was a project that isn't ever intending to see production. It is the basics of what a mix between NATS and Warpstream (kafka) would look like. Basically I wanted to experiment with a diskless message queue, using simpler clients than what kubernetes requires.
|
|
||||||
|
|
||||||
I did achieve that goal and have found more gains since this was published. I basically ended the project as I achieved what I wanted, but also that developing it into a full project would take too much time and finagling. I'll definitely continue on this path in the future, but for now it is on ice.
|
|
||||||
|
|
||||||
During ingest it could handle 500k messages a second at a uniform 1-200KiB payload size. It was too much for my home network, as I've only got 1GB ethernet in the house, so using local sockets it could do as much throughput as I could throw at it pretty much.
|
|
||||||
|
|
||||||
[nostore](https://git.kjuulh.io/kjuulh/nostore)
|
|
||||||
|
|
||||||
Again not really documented.
|
|
||||||
|
|
||||||
## Libraries
|
|
||||||
|
|
||||||
I like to explore various angles for libraries, we're continuing the namespacing, these are the most recently ones created.
|
|
||||||
|
|
||||||
### Nocontrol
|
|
||||||
|
|
||||||
I like kubernetes, I don't like maintaining it though. Nocontrol brings the strength of kubernetes controllers and manifests into Rust, and only ever Rust. It is basically a library that allows you to write reconcilers around maintained resources that can be allocated to certain rust processes in a decentralized manner.
|
|
||||||
|
|
||||||
As opposed to kubernetes Nocontrol is lease based. This is as opposed to the strong consistency raft based kubernetes control plane. What this in practice means is that you can have as few or as many nocontrol nodes as you want. Each of them simply check out / steal resources they can get ahold of. This requires a backing store, currently only postgresql is implemented, but adding others are easy ;). I just don't have a need for other types of databases.
|
|
||||||
|
|
||||||
This is a big change, and as such Nocontrol relies on actor based semantics (supervisors) to implement certain logic, whereas it would be easier in kubernetes to distribute this work.
|
|
||||||
|
|
||||||
Basically to achieve a Deployment setup.
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(Clone, Serialize, Deserialize)]
|
|
||||||
pub enum Specifications {
|
|
||||||
Deployment(DeploymentManifest),
|
|
||||||
Pod(PodManifest),
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
A spec is defined, the above is similar to how a deployment / pod operator would work.
|
|
||||||
|
|
||||||
You then setup an operator that handles reconciliation of resources, making sure they stay in the desired state
|
|
||||||
|
|
||||||
```rust
|
|
||||||
impl Operator for MyOperator {
|
|
||||||
type Specifications = Specifications;
|
|
||||||
type Error = anyhow::Error;
|
|
||||||
|
|
||||||
async fn reconcile(
|
|
||||||
&self,
|
|
||||||
manifest_state: &mut ManifestState<Specifications>,
|
|
||||||
) -> anyhow::Result<Action> {
|
|
||||||
todo!()
|
|
||||||
}
|
|
||||||
|
|
||||||
// A few extra methods to optionally implement
|
|
||||||
// async fn on_lease_lost() -> ...
|
|
||||||
// async fn on_error() -> ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
To develop a deployment operator, you would simply have a resource for the deployment, the deployment would then in turn using the control_plane api create / maintain resources for the pods. If the deployment notices there are too few, it will add more resources, and if there are too many it will take them away.
|
|
||||||
|
|
||||||
Simple as that, it isn't perfect and of course doesn't offer all the use-cases of kubernetes. It is still quite barebones, and I plan to add more to it. Because what I actually want to solve is not deployments at all, but rather a way to distribute data pipelines across many nodes.
|
|
||||||
|
|
||||||
I built this spec for my current schema applier at work
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
metadata:
|
|
||||||
name: experiences-core-events-event-createdv1
|
|
||||||
spec:
|
|
||||||
kind: StreamingIngest
|
|
||||||
state: Running
|
|
||||||
config:
|
|
||||||
schema_type: Protobuf
|
|
||||||
schema: | # proto
|
|
||||||
syntax = "proto3";
|
|
||||||
|
|
||||||
package dynamo.experiences_core.events.event.createdv1.v1;
|
|
||||||
|
|
||||||
import "canopy/options.proto";
|
|
||||||
|
|
||||||
message EventCreatedV1 {
|
|
||||||
option (canopy.topic) = "experiences-core.events.event.CreatedV1";
|
|
||||||
|
|
||||||
// .. removed for brevity
|
|
||||||
|
|
||||||
map<string, string> canopy_metadata = 9;
|
|
||||||
}
|
|
||||||
proto_path: dynamo/experiences-core/events/event/createdv1/v1/schema.proto
|
|
||||||
proto_package: dynamo.experiences_core.events.event.createdv1.v1.EventCreatedV1
|
|
||||||
input_table: schema__experiences_core_events_event_createdv1
|
|
||||||
topic: experiences-core.events.event.CreatedV1
|
|
||||||
environment: production
|
|
||||||
input_topic: canopy.product.dynamo.enriched.{{ environment }}.{{ key }}
|
|
||||||
output_topic: canopy.product.dynamo.structured.{{ environment }}.{{ key }}
|
|
||||||
```
|
|
||||||
|
|
||||||
This simply always make sure that a pod handles a pipeline, it can even have metadata for stored offsets and more for kafka. I like it, and it works quite well. I got claude to build a small tui like k9s for it, which is quite nifty, such that I can change the manifests at runtime using apis. This for example allows me to trigger a backfill of data etc.
|
|
||||||
|
|
||||||
link: [nocontrol](https://git.kjuulh.io/kjuulh/nocontrol)
|
|
||||||
|
|
||||||
However, I needed something to actually run the jobs, and my existing tools didn't cut it. So next up is how I run the pipelines
|
|
||||||
|
|
||||||
### Noprocess
|
|
||||||
|
|
||||||
Noprocess is basically Rust tokio tasks as processes. It allows me a shared registry where I can start, stop, kill processes on demand. This is a way to ensure I always only run one process at once per name, catch failed processes and more.
|
|
||||||
|
|
||||||
It allows graceful stopping and killing (SIGINT / SIGKILL) in terms of tokio tasks, without being too disruptive, and fairly ergonomic to work with.
|
|
||||||
|
|
||||||
The above nocontrol uses noprocess kind of like how you'd use a docker client. We basically just spawn work that we need to spawn, and kill it / let it crash if required.
|
|
||||||
|
|
||||||
To me in combination it brings parts of what makes Erlang / Elixir great into what I like about Kubernetes.
|
|
||||||
|
|
||||||
Because tokio tasks are so lightweight, it can handle millions of tasks at once, though probably not recommended, and not what it was developed for. It is a little slow (single lock) in spawning tasks, and I intend to keep it that way to prevent misuse.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
```rust
|
|
||||||
use noprocess::{Process, ProcessHandler, ProcessManager, ProcessResult};
|
|
||||||
use tokio_util::sync::CancellationToken;
|
|
||||||
|
|
||||||
struct MyPipeline;
|
|
||||||
|
|
||||||
impl ProcessHandler for MyPipeline {
|
|
||||||
async fn call(&self, cancel: CancellationToken) -> anyhow::Result<ProcessResult> {
|
|
||||||
async move {
|
|
||||||
loop {
|
|
||||||
tokio::select! {
|
|
||||||
_ = cancel.cancelled() => break,
|
|
||||||
_ = do_work() => {}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
#[tokio::main]
|
|
||||||
async fn main() -> anyhow::Result<()> {
|
|
||||||
let manager = ProcessManager::new();
|
|
||||||
|
|
||||||
let id = manager.add_process(Process::new(MyPipeline)).await;
|
|
||||||
manager.start_process(&id).await?;
|
|
||||||
|
|
||||||
// Later: stop, restart, or kill
|
|
||||||
manager.stop_process(&id).await?;
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Developed partially with Claude Code, it is subject to change, and I am probably gonna rip out the parts that claude made, as it made start / stopping overly complex.
|
|
||||||
|
|
||||||
## Work
|
|
||||||
|
|
||||||
I won't go into too much detail here, as I will likely share more on our company blog, once I get that set up. But during last year, I set up most of our current data platform stack, using a mix of DuckDb, RisingWave and clickhouse and a bunch of custom tooling as seen above.
|
|
||||||
|
|
||||||
We're at a stage where we don't really need too much scale, so it is all about ergonomics, which is why i developed nocontrol, as that allows an LLM to for example develop schemas for first and third party data sources. As well as Fungus our data contract tool, which I will share details on at some point as well.
|
|
||||||
|
|
||||||
# Conclusion
|
|
||||||
|
|
||||||
I think that is it for last year. I love developing stuff, and even if 2025 was a busy year for me, I still got a lot done which I am happy with. Not as much as I'd wanted, but looking back I did do a few projects that I like ;)
|
|
||||||
|
|
||||||
PS: I realize the post can come off as braggy, do know that I didn't replace Kubernetes, Kafka, etc. I simply developed a version of them that fits my needs, which if you do the same exercise will find out is a vastly smaller subset of features than the full project. So have fun with it, and go develop something.
|
|
||||||
|
|
||||||
> Also if you'd like to develop stuff together, I've recently started [rawpotion](https://rawpotion.io) basically a community of developers building cool stuff together, I offer mentoring sessions as well for getting started in there.
|
|
||||||
@@ -1,127 +0,0 @@
|
|||||||
---
|
|
||||||
type: blog-post
|
|
||||||
title: "Tales of the Homelab I: Moving is fun"
|
|
||||||
description: We all make mistakes, here is one of mine as I shared the tales of my homelab hobby. Revenge of the SSDs
|
|
||||||
draft: false
|
|
||||||
date: 2026-01-23
|
|
||||||
updates:
|
|
||||||
- time: 2026-01-23
|
|
||||||
description: first iteration
|
|
||||||
tags:
|
|
||||||
- "#blog"
|
|
||||||
- "#homelab"
|
|
||||||
---
|
|
||||||
|
|
||||||
I love my homelab. It is an amalgamation of random machines both efficient and not, hosted and not, pretty janky overall. A homelab reflects a lot about what kind of operator you are. It’s a hobby, and we all come from different backgrounds with different interests.
|
|
||||||
|
|
||||||
Some like to replace applications when Google kills them, some like to tinker and nerd out about performance, others like to build applications. I like to own my data, kid myself into believing it’s cheaper (it isn’t, electricity and hardware ain’t cheap, y’all), and I like to just build stuff, if that wasn’t apparent from the previous post.
|
|
||||||
|
|
||||||
A homelab is a term that isn’t clearly defined. To me, it’s basically the meme:
|
|
||||||
|
|
||||||
> Web: here is the cloud
|
|
||||||
> Hobbyist: cloud at home
|
|
||||||
|
|
||||||
It can be anything from a Raspberry Pi, to an old Lenovo ThinkPad, to a full-scale rack with enterprise gear and often several of those states exist at the same time.
|
|
||||||
|
|
||||||
My homelab is definitely in that state: various Raspberry Pis, mini PCs, old workstations, network gear, etc. I basically have two sides to my homelab. One is my media / home-related stuff; the other is my software brain, with PCs running Kubernetes, Docker, this blog, and so on.
|
|
||||||
|
|
||||||
It all started with one of my mini PCs. It has a few NVMe drives and runs Proxmox (basically a virtual machine hypervisor datacenter at home). It runs:
|
|
||||||
|
|
||||||
* Home Assistant, where it all started I needed an upgrade from running it on a Raspberry Pi
|
|
||||||
* MinIO (S3 server)
|
|
||||||
* Vault (secrets provider)
|
|
||||||
* Drone (CI runner)
|
|
||||||
* Harbor...
|
|
||||||
* Renova...
|
|
||||||
* Zitadel...
|
|
||||||
* Todo...
|
|
||||||
* Blo...
|
|
||||||
* Gi...
|
|
||||||
* P...
|
|
||||||
|
|
||||||
In total: **19 VMs**.
|
|
||||||
|
|
||||||
You might be saying and I don’t want to hear it that this is simply too many. A big, glaring single point of failure. Foreshadowing, right there.
|
|
||||||
|
|
||||||
My other nodes run highly available Kubernetes with replicated storage and so on. They do, however, depend on the central node for database and secrets.
|
|
||||||
|
|
||||||
## Moving
|
|
||||||
|
|
||||||
So, I was moving, and a little bit stressed because I was starting a new job at the same time (day, idiot). I basically packed everything into boxes / the back of my car and moved it.
|
|
||||||
|
|
||||||
It took about a week before I got around to setting up my central mini PC again, as I simply began to miss my Jellyfin media center filled with legally procured media, I assure you.
|
|
||||||
|
|
||||||
I didn’t think too much of it. Plugged it in on top of a kitchen counter, heard it spin up... and nothing came online. I’ve got monitoring for all my services, and none of it resolved. Curious.
|
|
||||||
|
|
||||||
I grabbed a spare screen and plugged it in.
|
|
||||||
|
|
||||||
```bash
|
|
||||||
systemd zfs-import.want: zfs pool unable to mount zfs-clank-pool
|
|
||||||
```
|
|
||||||
|
|
||||||
Hmm. Very much *hmm*. Smells like hardware failure, but no panic yet.
|
|
||||||
|
|
||||||
I had an SSD in the box the one used for all the VM volumes. I’d noticed it had been a little loose before, but it hadn’t been a problem. The enclosure is meant for a full HDD, not a smaller SSD.
|
|
||||||
|
|
||||||
I tried reseating the SSD. No luck.
|
|
||||||
|
|
||||||
Slightly panicky now, I found another PC and plugged the SSD into that to check whether it was just the internal connector.
|
|
||||||
|
|
||||||
Nope. Nope. Dead SSD. Absolutely dead.
|
|
||||||
|
|
||||||
The box wouldn’t boot without the ZFS pool, so I needed a way to stop that from happening. Using live boot Linux usb, I could disable the ZFS import and reboot.
|
|
||||||
|
|
||||||
The Proxmox UI, however, was a bloodbath.
|
|
||||||
|
|
||||||
**0/19 VMs running.**
|
|
||||||
F@ck.
|
|
||||||
|
|
||||||
As it turns out, there’s sometimes a reason we do the contingencies we do professionally high availability setups, 3-2-1 backup strategies, etc. Even though my services had enjoyed ~99% uptime until then, the single point of failure struck, leaving a lot of damage.
|
|
||||||
|
|
||||||
The way I had `designed` my VM installations was by using a separate boot drive and volume drive. This is a feature of KVM / Proxmox and allows sharing a base OS boot disk while separating actual data. It’s quite convenient and keeps VMs slim.
|
|
||||||
|
|
||||||
My Debian base image was about 20 GB. That would’ve been 20 GB × 19 VMs. Not terrible and honestly, I would’ve paid that cost if I’d been paying attention.
|
|
||||||
|
|
||||||
Instead, I was left with VMs that wouldn’t boot because their boot disk was gone. Like a head without a body. [A dog without a bone](https://youtu.be/ubWL8VAPoYw?si=iDd3Xk6NCkF1UkRV).
|
|
||||||
|
|
||||||
After a brief panic actually quite brief I checked what mattered first: backups. And yes, the important things (code in Gitea, family data) were all backed up and available. I should’ve tested my contingencies better, but at least monitoring worked.
|
|
||||||
|
|
||||||
I restored the most important services on one of my old workstations that I use for development.
|
|
||||||
|
|
||||||
I *did* have backups of the VMs... but they were backed up to the same extra drive that had failed.
|
|
||||||
|
|
||||||
That was dumb.
|
|
||||||
|
|
||||||
However, I had a theory. I could replace the missing boot disks with new ones and reattach them to the existing VM data disks. Basically, give the dog its bone back.
|
|
||||||
|
|
||||||
It was not fun but I managed to restore Matrix, Home Assistant, this blog, Drone, PostgreSQL, and Gitea. Those were the ones I cared about most and that were actually recoverable. The rest had their data living exclusively on the dead disk.
|
|
||||||
|
|
||||||
I may or may not share how I fixed it. It’s been a while, and I’d have to reconstruct all the steps. So probably not.
|
|
||||||
|
|
||||||
At this point, my Kubernetes cluster was basically *borked* (if you know, you know). All the data was there, but none of the services worked most of them depended on secrets from Vault, which was gone.
|
|
||||||
|
|
||||||
So I had to start over. Pretty much.
|
|
||||||
|
|
||||||
It wasn’t a huge loss, though. All my data lived in Postgres backups, and all configuration was stored GitOps-style in Gitea.
|
|
||||||
|
|
||||||
## Postmortem
|
|
||||||
|
|
||||||
I never fully restored all the VMs and that’s fine. I *could* have, but this was also a good opportunity to improve my setup and finally move more things into highly available compute. It was also a chance to replace components I wasn’t happy with. Basically the eternal cycle of a homelab.
|
|
||||||
|
|
||||||
Harbor was one of them. It’s heavy and fragile. Basically, all my Java services had to go. Not because I hate Java but because they’re often far too resource-intensive for a homelab running on mini PCs. I can’t have services consuming all RAM and CPU for very little benefit.
|
|
||||||
|
|
||||||
Since then, I’ve significantly improved my backup setup. I now use proper mirrored RAID setups on my workstations for both workloads and backups, plus an offsite backup.
|
|
||||||
|
|
||||||
> Fun fact: as I was building my new backup setup, I had another of these SSDs fail on me. That is 2/3 of my EVO Samsung SSDs I don't think I am going to be buying these again.
|
|
||||||
|
|
||||||
* ZFS with zrepl
|
|
||||||
* Borgmatic / BorgBackup for offsite
|
|
||||||
* PostgreSQL incremental backups with pgBackRest
|
|
||||||
|
|
||||||
Everything is monitored. I also replaced five different Grafana services with a single monitoring platform built on OpenTelemetry and SigNoz. It works well, though replacing PromQL with SQL definitely has some growing pains.
|
|
||||||
|
|
||||||
In the next post, I’ll probably share how I do compute, Kubernetes from home and maybe another homelab oops, like the time I nearly lost all my family’s Christmas wishes 😉
|
|
||||||
|
|
||||||
I swear I’m a professional. But we all make mistakes sometimes. What matters is learning from them and fixing problems even when they seem impossible. I am also not a millionaire, so for my home lab I neither have the budget or the time to build fault-tolerant services. I try my best, especially for my own software, which I've never had problems with, but many other services just aren't built for high availability, requires very high resource requirements, setups, or simply just an enterprise license. I put in the effort where it is most fun and rewarding to work, and that is what having a home lab is all about.
|
|
||||||
|
|
||||||
Have a great Friday, and I hope to see you in the next post.
|
|
||||||
@@ -1,157 +0,0 @@
|
|||||||
---
|
|
||||||
type: blog-post
|
|
||||||
title: "Incidental Complexity"
|
|
||||||
description: |
|
|
||||||
Complexity is a required aspect of developing products, in especially software, complexity is sometimes inherited, molded and incidental.
|
|
||||||
In this post we discuss incidental complexity in software development; history, present and speculation on the future.
|
|
||||||
draft: false
|
|
||||||
date: 2026-01-25
|
|
||||||
updates:
|
|
||||||
- time: 2026-01-25
|
|
||||||
description: first iteration
|
|
||||||
tags:
|
|
||||||
- "#blog"
|
|
||||||
- "#softwaredevelopment"
|
|
||||||
- "#ai"
|
|
||||||
- "#complexity"
|
|
||||||
- "#techdebt"
|
|
||||||
---
|
|
||||||
|
|
||||||
Complexity is a required side effect of developing products, whether in processes, human relations, or especially software.
|
|
||||||
|
|
||||||
Complexity is sometimes inherited. You have to fix an issue in a legacy system, make it fit for purpose, and either expand or refactor its capabilities and internal workings.
|
|
||||||
|
|
||||||
Or it is incidental, which we will cover in this post: whether you add more than you should to cover a need you think you have, only to discover that the result is over-engineered or simply redundant. That is not to say the code is unused, but it represents extra details that could have been simpler.
|
|
||||||
|
|
||||||
## Incidental complexity has always existed
|
|
||||||
|
|
||||||
Complexity is a feature, not a bug. One of the main benefits of software is that it is so malleable. It can be changed much more easily than hardware. It is far easier to change a line of code than to redesign a production line.
|
|
||||||
|
|
||||||
Software also has no real permanence outside of organizational or environmental factors. It must live up to requirements, both functional ones, such as fulfilling a purpose, and non-functional ones, such as handling certain constraints reliably. A trading algorithm, for example, has a specific shape because it must be fast enough to beat competitors.
|
|
||||||
|
|
||||||
Complexity is born when a decision, whether incidental or not, is added to a product. It might be a choice of programming language, coding style, infrastructure, and so on. None of these are inherently good or bad, but they exist on a scale of how easy they are to discover and change. This varies depending on context: firmware distributed once, over-the-air updates, data center services, or websites that change many times per day.
|
|
||||||
|
|
||||||
I define two subsets of complexity: emergent and incidental. The goal of most software is to be the minimal amount required to fulfill its requirements. This is not about lines of code. Rather, it is about how much context is embedded in the system for it to function. That is emergent complexity.
|
|
||||||
|
|
||||||
Incidental complexity arises when we apply too much context. These are details that are unnecessary or irrelevant to solving the problem.
|
|
||||||
|
|
||||||
### Example
|
|
||||||
|
|
||||||
A requirement might be to show a list of users on a webpage. The list comes from a database, and there are many ways to solve this.
|
|
||||||
|
|
||||||
- A simple solution is to fetch users one by one using the database client until the page is populated. If the service will never have more than ten users, this is fast enough, easy to change, and perfectly adequate.
|
|
||||||
- A complex solution might cache the total number of users, split queries into batches, fetch them in parallel, and stitch the results together.
|
|
||||||
|
|
||||||
Both solutions are valid. They produce the same output using different approaches.
|
|
||||||
|
|
||||||
If the database never has more than ten users, then much of the complex solution becomes unnecessary. Batch processing, parallelization, counting, and stitching are never used in practice.
|
|
||||||
|
|
||||||
All the logic required to handle thousands of users exists, but is never actually exercised. If the batch size is 500, then no parallel processing occurs, no splitting is needed, and no stitching is required, the code is still run, but was never required in the first place.
|
|
||||||
|
|
||||||
There is no right or wrong answer. The first solution was built knowing that ten users was the maximum, so it was designed to handle that within reason. It is also simple enough to change if this assumption ever changes. The second solution may have been built with the ambition of handling thousands of users and providing fast page loads.
|
|
||||||
|
|
||||||
Incidental complexity consists of additional details that have little or no effect on the actual output, whether functional or non-functional. You might argue that this is simply premature complexity. I define premature complexity as a step in the process that often leads to incidental complexity.
|
|
||||||
|
|
||||||
It is impossible to hit the mark perfectly. Complexity is subjective. For an experienced team with a wide toolbox, fetching one thousand items at once may be trivial and acceptable. For others, fetching items one by one may be simpler and safer.
|
|
||||||
|
|
||||||
There is no universally correct answer. What matters is that software is built to its requirements, with minimal additional details. A good solution should feel natural given the organizational context and problem domain.
|
|
||||||
|
|
||||||
Incidental complexity often appears in questions such as: Why does this use batching when there is only one item to fetch? Why does this use a strategy pattern when there is only one option?
|
|
||||||
|
|
||||||
Some of these complexities may become useful in the future, but at present they do not contribute meaningfully to solving the problem. You can likely think of many examples from your own career, whether created by you or inherited from others.
|
|
||||||
|
|
||||||
## Devil in the details
|
|
||||||
|
|
||||||
It can be very difficult to distinguish between emergent and incidental complexity. This is truly where the devil is in the details.
|
|
||||||
|
|
||||||
Continuing the previous example, it might be that every Easter, volunteers across Denmark are added to the database. Instead of 10 users, there are suddenly 1000. In that situation, the page might have unsatisfactory performance in loading the page without a sufficiently complex solution.
|
|
||||||
|
|
||||||
This gives complexity a form of permanence. It becomes difficult to remove because similar situations may have caused failures in the past. When performing rewrites or maintenance, teams often hesitate to remove such logic because it may have been added for a good reason.
|
|
||||||
|
|
||||||
Sometimes, you cannot know for certain. You have to take a risk. Doing so requires skill, experience, and intention. Risk is uncomfortable, especially in production systems.
|
|
||||||
|
|
||||||
In general, teams are more likely to preserve inherited complexity than complexity in newly written code. This is one reason why solving a subset of a problem from scratch is often easier than modifying an existing solution, but also often leaves out crucial details.
|
|
||||||
|
|
||||||
## Human vs. AI (LLM)
|
|
||||||
|
|
||||||
Humans and AI (Agents and LLMs) produce incidental complexity in similar ways, but with important differences.
|
|
||||||
|
|
||||||
A human applies personal knowledge and programming style to a problem and arrives at a solution. Humans are usually aware of the requirements and context, even if imperfectly. Incidental complexity arises from habits, preferences, and experience.
|
|
||||||
|
|
||||||
An AI has wide but fuzzy knowledge. It does not have taste, but it does have style, derived from aggregated training data and optimization for producing acceptable answers. Solving problems is part of that optimization, but so are clarity, verbosity, and perceived completeness.
|
|
||||||
|
|
||||||
AI systems often have limited understanding of the real context. Conveying full organizational and business context through text alone is extremely difficult. A large part of engineering work consists of deriving concrete requirements from incomplete information.
|
|
||||||
|
|
||||||
As a result, AI systems often produce solutions that appear to work but either omit crucial details or introduce functional and non-functional requirements that were never requested.
|
|
||||||
|
|
||||||
There is also the issue of ephemeral context. AI systems forget details over time, which can lead to severe degradation in performance. Even if this problem is solved, AI agents are still likely to produce different forms of incidental complexity than humans.
|
|
||||||
|
|
||||||
Humans and AI are tuned to different incentives. Humans are shaped by values, experience, and feedback, which leads to effective but relatively slow development. Large language models are trained on vast amounts of software of varying quality. They are optimized to generate outputs that are accepted, not necessarily correct.
|
|
||||||
|
|
||||||
This distinction is crucial. An acceptable answer is not the same as a correct one. This is comparable to a student lying about failing a class. The behavior exists because of incentives, and it is unlikely to disappear entirely.
|
|
||||||
|
|
||||||
AI systems are biased toward producing an answer even with limited context. They are also optimized to minimize follow-up questions. This often results in confident but incomplete solutions.
|
|
||||||
|
|
||||||
This tendency often appears in how AI systems structure their responses. They frequently add extensive comments explaining obvious behavior, regardless of complexity. When producing text, they default to a familiar pattern: an introduction, several bullet points, and a conclusion.
|
|
||||||
|
|
||||||
These tendencies can be influenced, but the underlying style remains consistent. The same applies to programming output. Given no examples, an agent will typically produce an average, generic solution.
|
|
||||||
|
|
||||||
At the current stage of development in 2026, AI systems often add details that are irrelevant to the actual context. Because they operate in an information vacuum, they compensate by over-specifying solutions.
|
|
||||||
|
|
||||||
A similar outcome would occur if you gave a contractor two paragraphs of instructions and then sent them away for a month without feedback. The resulting solution would likely contain many assumptions and unnecessary features.
|
|
||||||
|
|
||||||
AI agents behave in a comparable way. Because of their training, they develop a distinctive style that often introduces superfluous components. Even more problematically, they tend to treat their own incidental complexity as a features rather than as a liability.
|
|
||||||
|
|
||||||
They also struggle to distinguish between emergent and incidental complexity.
|
|
||||||
|
|
||||||
This often forces operators to continuously refine and correct the agent’s output by providing more context. In practice, this interaction often looks like this:
|
|
||||||
|
|
||||||
- Human: Create a web page to display a list of users.
|
|
||||||
- Agent: Here is a webpage that shows a list of users, including name, birthdate, username, and email, with a details page.
|
|
||||||
- Human: I did not ask for a details page, and users do not have usernames or emails. They only have a name and an ID.
|
|
||||||
- Agent: Compacts context.
|
|
||||||
- Agent: Here is a list with name and ID, and no details page.
|
|
||||||
|
|
||||||
The result appears correct, but hidden complexity may remain. The database schema may still contain unused fields. Migration logic may exist for data that will never be populated. Authentication hooks or unused endpoints may still be present.
|
|
||||||
|
|
||||||
That is incidental complexity.
|
|
||||||
|
|
||||||
The agent may eventually arrive at the correct solution through repeated refinement, either with human guidance or assistance from other agents. However, this raises the question of cost.
|
|
||||||
|
|
||||||
## The Cost
|
|
||||||
|
|
||||||
It is not uncommon for such workflows to leave behind multiple unused tables, unconnected components, dormant endpoints, and unnecessary abstractions.
|
|
||||||
|
|
||||||
I generally avoid focusing on lines of code, but in practice AI-generated systems often contain significantly more source code, comments, helper functions, and documentation than necessary. Much of this material reflects a distorted view of what is important for future maintainers, whether human or machine.
|
|
||||||
|
|
||||||
Ironically, this also makes the system harder for future AI agents to work with. Context is critical for large language models. Filling a codebase with irrelevant details consumes context window capacity and reduces the effectiveness of future interactions.
|
|
||||||
|
|
||||||
AI agents are a genuine productivity multiplier. They can produce text and code far faster than humans. They can explore solution spaces quickly and enable many new groups to build software.
|
|
||||||
|
|
||||||
This includes small organizations that need custom tools but cannot afford dedicated engineers, as well as engineers who can now serve smaller customers efficiently.
|
|
||||||
|
|
||||||
However, the solutions produced by AI agents frequently contain hidden technical debt in the form of incidental complexity. In many cases, this debt outweighs the initial productivity gains by constraining future development.
|
|
||||||
|
|
||||||
Systems become harder to understand, harder to modify, and harder to extend. Over time, the accumulated friction erodes the benefits that automation originally provided.
|
|
||||||
|
|
||||||
Often conflated, incidental becomes because of AI systems accidental complexity. It is something that happens because of a mistake, or negligence, in the case of agents unintentional.
|
|
||||||
|
|
||||||
## My view of the future
|
|
||||||
|
|
||||||
AI agents are not going away. They solve problems at lower marginal cost than human engineers, and this advantage is decisive.
|
|
||||||
|
|
||||||
However, their output requires intentional correction and refinement. This can be done by humans, by other agents, or by hybrid workflows. Without such intervention, complexity will continue to accumulate.
|
|
||||||
|
|
||||||
I believe that, without additional context and governance, autonomous systems will tend to produce more entropy. Problems may be solved in the short term, but systems will degrade in quality over time.
|
|
||||||
|
|
||||||
This is similar to sending a contractor to a remote cabin for two months with minimal guidance and then offering only a paragraph of feedback at the end. The solution may function, but its internal structure will reflect distorted priorities and hidden assumptions. Sending a village doesn't work either. You might end up with amazing code quality, well-documented code. But if it is over-engineered, containing superfluous details, then it doesn't matter.
|
|
||||||
|
|
||||||
Such systems often contain layers of incidental complexity that require deliberate effort to untangle.
|
|
||||||
|
|
||||||
For this reason, I believe software engineers will continue to play a central role in product development for the foreseeable future. That role will evolve, but it will not disappear.
|
|
||||||
|
|
||||||
Nothing so far suggests that autonomous systems can reliably produce sustained order from complexity. Until they can operate at the level of entire organizations, with deep contextual awareness and accountability, they will remain dependent on human input.
|
|
||||||
|
|
||||||
As long as AI systems must interact with human-created systems to fill their information gaps, engineers will remain essential to maintaining coherence, intent, and long-term quality. What is a side-effect however, is that we will have much more code going forward, with many bespoke components, as the cost of producing functionality goes to zero, so will the need for centralized services, and in turn bespoke components will continue to climb if left unchallenged.
|
|
||||||
|
|
||||||
In the coming years and decades, I expect that software products and interactions will accumulate so much complexity that they will become indistinguishable from biological systems, even more so than they already are today. We will need agents to untangle the mess, but also surgical knowledge for when to refine a component to something known.
|
|
||||||
@@ -1,6 +1,3 @@
|
|||||||
[env]
|
|
||||||
_.file = ".env"
|
|
||||||
|
|
||||||
[tasks."ci:build"]
|
[tasks."ci:build"]
|
||||||
dir = "./ci"
|
dir = "./ci"
|
||||||
run = "cargo build"
|
run = "cargo build"
|
||||||
|
|||||||
24
yarn.lock
24
yarn.lock
@@ -67,13 +67,10 @@
|
|||||||
tailwindcss "^2.0.1"
|
tailwindcss "^2.0.1"
|
||||||
|
|
||||||
"@tailwindcss/typography@^0.5.9":
|
"@tailwindcss/typography@^0.5.9":
|
||||||
version "0.5.9"
|
version "0.5.19"
|
||||||
resolved "https://registry.yarnpkg.com/@tailwindcss/typography/-/typography-0.5.9.tgz#027e4b0674929daaf7c921c900beee80dbad93e8"
|
resolved "https://registry.yarnpkg.com/@tailwindcss/typography/-/typography-0.5.19.tgz#ecb734af2569681eb40932f09f60c2848b909456"
|
||||||
integrity sha512-t8Sg3DyynFysV9f4JDOVISGsjazNb48AeIYQwcL+Bsq5uf4RYL75C1giZ43KISjeDGBaTN3Kxh7Xj/vRSMJUUg==
|
integrity sha512-w31dd8HOx3k9vPtcQh5QHP9GwKcgbMp87j58qi6xgiBnFFtKEAgCWnDw4qUT8aHwkCp8bKvb/KGKWWHedP0AAg==
|
||||||
dependencies:
|
dependencies:
|
||||||
lodash.castarray "^4.4.0"
|
|
||||||
lodash.isplainobject "^4.0.6"
|
|
||||||
lodash.merge "^4.6.2"
|
|
||||||
postcss-selector-parser "6.0.10"
|
postcss-selector-parser "6.0.10"
|
||||||
|
|
||||||
"@types/parse-json@^4.0.0":
|
"@types/parse-json@^4.0.0":
|
||||||
@@ -600,21 +597,6 @@ lines-and-columns@^1.1.6:
|
|||||||
resolved "https://registry.yarnpkg.com/lines-and-columns/-/lines-and-columns-1.2.4.tgz#eca284f75d2965079309dc0ad9255abb2ebc1632"
|
resolved "https://registry.yarnpkg.com/lines-and-columns/-/lines-and-columns-1.2.4.tgz#eca284f75d2965079309dc0ad9255abb2ebc1632"
|
||||||
integrity sha512-7ylylesZQ/PV29jhEDl3Ufjo6ZX7gCqJr5F7PKrqc93v7fzSymt1BpwEU8nAUXs8qzzvqhbjhK5QZg6Mt/HkBg==
|
integrity sha512-7ylylesZQ/PV29jhEDl3Ufjo6ZX7gCqJr5F7PKrqc93v7fzSymt1BpwEU8nAUXs8qzzvqhbjhK5QZg6Mt/HkBg==
|
||||||
|
|
||||||
lodash.castarray@^4.4.0:
|
|
||||||
version "4.4.0"
|
|
||||||
resolved "https://registry.yarnpkg.com/lodash.castarray/-/lodash.castarray-4.4.0.tgz#c02513515e309daddd4c24c60cfddcf5976d9115"
|
|
||||||
integrity sha512-aVx8ztPv7/2ULbArGJ2Y42bG1mEQ5mGjpdvrbJcJFU3TbYybe+QlLS4pst9zV52ymy2in1KpFPiZnAOATxD4+Q==
|
|
||||||
|
|
||||||
lodash.isplainobject@^4.0.6:
|
|
||||||
version "4.0.6"
|
|
||||||
resolved "https://registry.yarnpkg.com/lodash.isplainobject/-/lodash.isplainobject-4.0.6.tgz#7c526a52d89b45c45cc690b88163be0497f550cb"
|
|
||||||
integrity sha512-oSXzaWypCMHkPC3NvBEaPHf0KsA5mvPrOPgQWDsbg8n7orZ290M0BmC/jgRZ4vcJ6DTAhjrsSYgdsW/F+MFOBA==
|
|
||||||
|
|
||||||
lodash.merge@^4.6.2:
|
|
||||||
version "4.6.2"
|
|
||||||
resolved "https://registry.yarnpkg.com/lodash.merge/-/lodash.merge-4.6.2.tgz#558aa53b43b661e1925a0afdfa36a9a1085fe57a"
|
|
||||||
integrity sha512-0KpjqXRVvrYyCsX1swR/XTK0va6VQkQM6MNo7PqW77ByjAhoARA8EfrP1N4+KlKj8YS0ZUCtRT/YUuhyYDujIQ==
|
|
||||||
|
|
||||||
lodash.topath@^4.5.2:
|
lodash.topath@^4.5.2:
|
||||||
version "4.5.2"
|
version "4.5.2"
|
||||||
resolved "https://registry.yarnpkg.com/lodash.topath/-/lodash.topath-4.5.2.tgz#3616351f3bba61994a0931989660bd03254fd009"
|
resolved "https://registry.yarnpkg.com/lodash.topath/-/lodash.topath-4.5.2.tgz#3616351f3bba61994a0931989660bd03254fd009"
|
||||||
|
|||||||
Reference in New Issue
Block a user